The new old Perfherder data model
Oct 23rd, 2015
I spent a good chunk of time last quarter redesigning how Perfherder stores its data internally. Here are some notes on this change, for posterity.
Perfherder’s data model is based around two concepts:
- Series signatures: A unique set of properties (platform, test name, suite name, options) that identifies a performance test.
- Series data: A set of measurements for a series signature, indexed by treeherder push and job information.
When it was first written, Perfherder stored the second type of data as a JSON-encoded series in a relational (MySQL) database. That is, instead of storing each datum as a row in the database, we would store sequences of them. The assumption was that for the common case (getting a bunch of data to plot on a graph), this would be faster than fetching a bunch of rows and then encoding them as JSON. Unfortunately this wasn’t really true, and it had some serious drawbacks besides.
First, the approach’s performance was awful when it came time to add new data. To avoid needing to decode or download the full stored series when you wanted to render only a small subset of it, we stored the same series multiple times over various time intervals. For example, we stored the series data for one day, one week: all the way up to one year. You can probably see the problem already: you have to decode and re-encode the same data structure many times for each time interval for every new performance datum you were inserting into the database. The pseudo code looked something like this for each push:
for each platform we're testing talos on:
for each talos job for the platform:
for each test suite in the talos job:
for each subtest in the test suite:
for each time interval in one year, 90 days, 60 days, ...:
fetch and decode json series for that time interval from db
add datapoint to end of series
re-encode series as json and store in dbConsider that we have some 6 platforms (android, linux64, osx, winxp, win7, win8), 20ish test suites with potentially dozens of subtests and you can see where the problems begin.
In addition to being slow to write, this was also a pig in terms of disk space consumption. The overhead of JSON ("{, }" characters, object properties) really starts to add up when you’re storing millions of performance measurements. We got around this (sort of) by gzipping the contents of these series, but that still left us with gigantic mysql replay logs as we stored the complete “transaction” of replacing each of these series rows thousands of times per day. At one point, we completely ran out of disk space on the treeherder staging instance due to this issue.
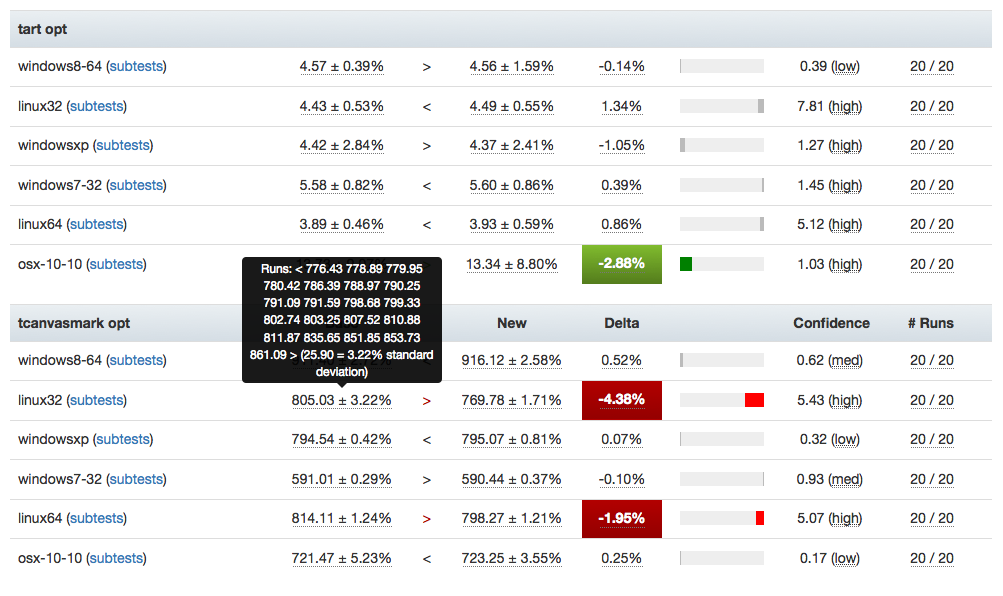
Read performance was also often terrible for many common use cases. The original assumption I mentioned above was wrong: rendering points on a graph is only one use case a system like Perfherder has to handle. We also want to be able to get the set of series values associated with two result sets (to render comparison views) or to look up the data associated with a particular job. We were essentially indexing the performance data only on one single dimension (time) which made these other types of operations unnecessarily complex and slow — especially as the data you want to look up ages. For example, to look up a two week old comparison between two pushes, you’d also have to fetch the data for every subsequent push. That’s a lot of unnecessary overhead when you’re rendering a comparison view with 100 or so different performance tests:
So what’s the alternative? It’s actually the most obvious thing: just encode one database row per performance series value and create indexes on each of the properties that we might want to search on (repository, timestamp, job id, push id). Yes, this is a lot of rows (the new database stands at 48 million rows of performance data, and counting) but you know what? MySQL is designed to handle that sort of load. The current performance data table looks like this:
+----------------+------------------+
| Field | Type |
+----------------+------------------+
| id | int(11) |
| job_id | int(10) unsigned |
| result_set_id | int(10) unsigned |
| value | double |
| push_timestamp | datetime(6) |
| repository_id | int(11) |
| signature_id | int(11) |
+----------------+------------------+MySQL can store each of these structures very efficiently, I haven’t done the exact calculations, but this is well under 50 bytes per row. Including indexes, the complete set of performance data going back to last year clocks in at 15 gigs. Not bad. And we can examine this data structure across any combination of dimensions we like (push, job, timestamp, repository) making common queries to perfherder very fast.
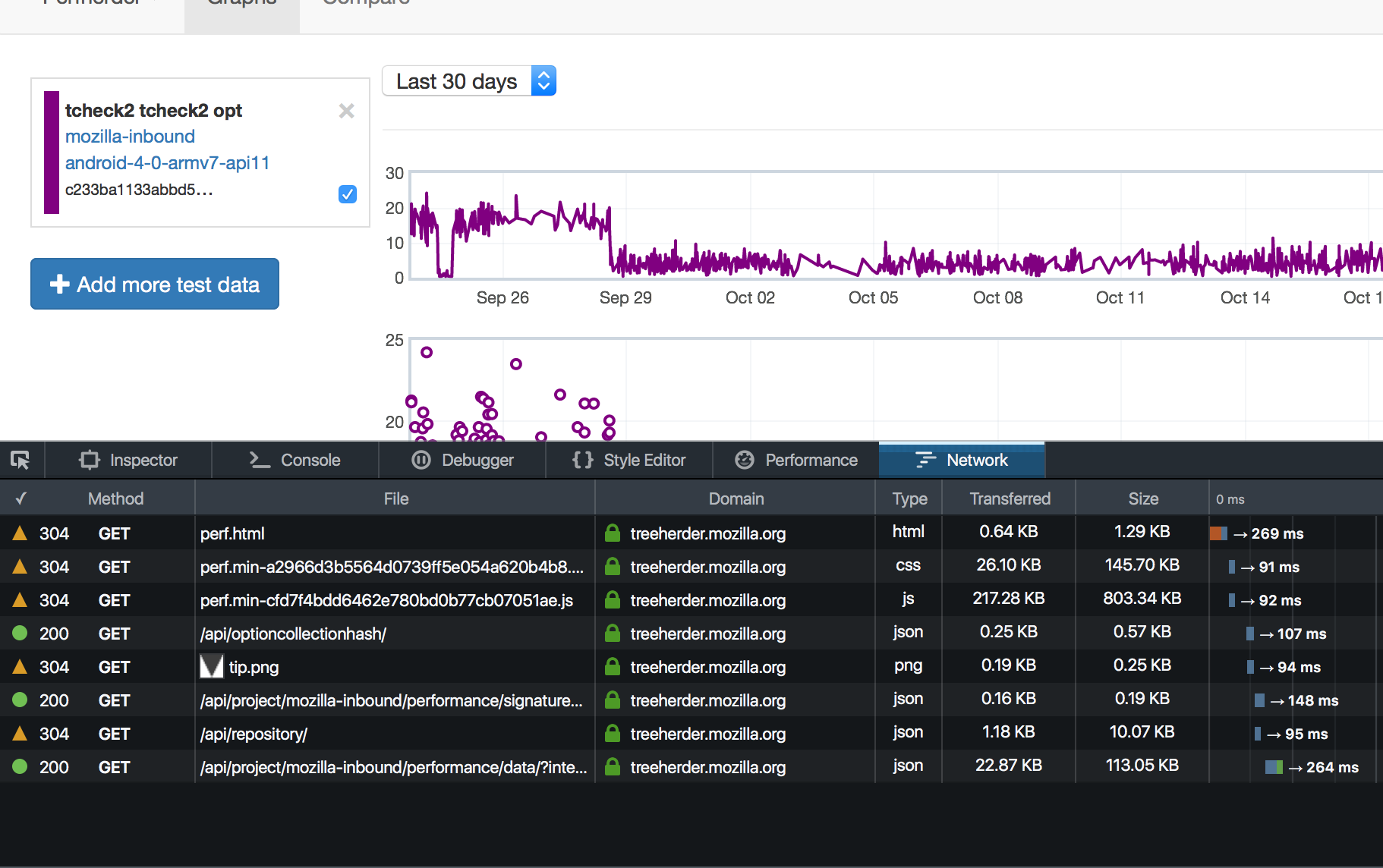
What about the initial assumption, that it would be faster to get a series out of the database if it’s already pre-encoded? Nope, not really. If you have a good index and you’re only fetching the data you need, the overhead of encoding a bunch of database rows to JSON is pretty minor. From my (remote) location in Toronto, I can fetch 30 days of tcheck2 data in 250 ms. Almost certainly most of that is network latency. If the original implementation was faster, it’s not by a significant amount.
Lesson: Sometimes using ancient technologies (SQL) in the most obvious way is the right thing to do. DoTheSimplestThingThatCouldPossiblyWork