A principled reorganization of docs.telemetry.mozilla.org
May 11th, 2020
(this post is aimed primarily at an internal audience, but I thought I’d go ahead and make it public as a blog post)
I’ve been thinking a bunch over the past few months about the Mozilla data organization’s documentation story. We have a first class data platform here at Mozilla, but using it to answer questions, especially for newer employees, can be quite intimidating. As we continue our collective journey to becoming a modern data-driven organization, part of the formula for unlocking this promise is making the tools and platforms we create accessible to a broad internal audience.
My data peers are a friendly group of people and we have historically been good at answering questions on forums like the #fx-metrics slack channel: we’ll keep doing this. That said, our time is limited: we need a common resource for helping bring people up to speed on how to use the data platform to answer common questions.
Our documentation site, docs.telemetry.mozilla.org, was meant to be this resource: however in the last couple of years an understanding of its purpose has been (at least partially) lost and it has become somewhat overgrown with content that isn’t very relevant to those it’s intended to help.
This post’s goal is to re-establish a mission for our documentation site — towards the end, some concrete proposals on what to change are also outlined.
Setting the audience
docs.telemetry.mozilla.org was and is meant to be a resource useful for data practitioners within Mozilla.
Examples of different data practioners and their use cases:
- A data scientist performing an experiment analysis
- A data analyst producing a report on the effectiveness of a recent marketing campaign
- A Firefox engineer trying to understand the performance characteristics of a new feature
- A technical product manager trying to understand the characteristics of a particular user segment
- A quality assurance engineer trying to understand the severity of a Firefox crash
There are a range of skills that these different groups bring to the table, but there are some common things we expect a data practitioner to have, whatever their formal job description:
- At least some programming and analytical experience
- Comfortable working with and understanding complex data systems with multiple levels of abstraction (for example: the relationship between the Firefox browser which produces Telemetry data and the backend system which processes it)
- The time necessary to dig into details
This also excludes a few groups:
- Senior leadership or executives: they are of course free to use docs.telemetry.mozilla.org if helpful, but it is expected that the type of analytical work covered by the documentation will normally be done by a data practitioner and that relevant concepts and background information will be explained to them (in the form of high-level dashboards, presentations, etc.).
- Data Engineering: some of the material on docs.telemetry.mozilla.org may be incidentally useful to this internal audience, but explaining the full details of the data platform itself belongs elsewhere.
What do these users need?
In general, a data practitioner is trying to answer a specific set of questions in the context of an exploration. There are a few things that they need:
- A working knowledge of how to use the technological tools to answer the questions they might have: for example, how to create a SQL query counting the median value of a particular histogram for a particular usage segment.
- A set of guidelines on best practices on how to measure specific things: for example, we want our people using our telemetry systems to use well-formulated practices for measuring things like “Monthly Active Users” rather than re-inventing such things themselves.
What serves this need?
A few years ago, Ryan Harter did an extensive literature review on writing documentation on technical subjects - the take away from this exploration is that the global consensus is that we should focus most of our attention on writing practical tutorials which enables our users to perform specific tasks in the service of the above objective.
There is a proverb, allegedly attributed to Confucius which goes something like this:
“I hear and I forget. I see and I remember. I do and I understand.”
The understanding we want to build is how to use our data systems and tools to answer questions. Some knowledge of how our data platform works is no doubt necessary to accomplish this, but it is mostly functional knowledge we care about imparting to data practitioners: the best way to build this understanding is to guide users in performing tasks.
This makes sense intuitively, but it is also borne out by the data that this is what our users are looking for. Looking through the top pages on Google Analytics, virtually all of them1 refer either to a cookbook or howto guide:
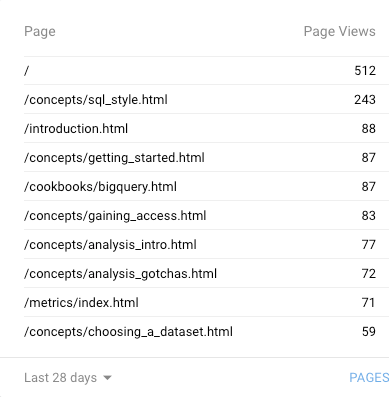
Happily, this allows us to significantly narrow our focus for docs.telemetry.mozilla.org. We no longer need to worry about:
- Providing lists or summaries of data tools available inside Mozilla2: we can talk about tools only as needed in the context of tasks they want to accomplish. We may want to keep such a list handy elsewhere for some other reason (e.g. internal auditing purposes), but we can safely say that it belongs somewhere else, like the Mozilla wiki, mana, or the telemetry.mozilla.org portal.
- Detailed reference on the technical details of the data platform implementation. Links to this kind of material can be surfaced inside the documentation where relevant, but it is expected that an implementation reference will normally be stored and presented within the context of the tools themselves (a good example would be the existing documentation for GCP ingestion).
- Detailed reference on all data sets, ping types, or probes: hand-written documentation for this kind of information is difficult to keep up to date with manual processes3 and is best generated automatically and browsed with tools like the probe dictionary.
- Detailed reference material on how to submit Telemetry. While an overview of how to think about submitting telemetry may be in scope (recall that we consider Firefox engineers a kind of data practitioner), the details are really a seperate topic that is better left to another resource which is closer to the implementation (for example, the Firefox Source Documentation or the Glean SDK reference).
Scanning through the above, you’ll see a common theme: avoid overly detailed reference material. The above is not to say that we should avoid background documentation altogether. For example, an understanding of how our data pipeline works is key to understanding how up-to-date a dashboard is expected to be. However, this type of documentation should be written bearing in mind the audience (focusing on what they need to know as data practitioners) and should be surfaced towards the end of the documentation as supporting material.
As an exception, there is also a very small amount of reference documentation which we want to put at top-level because it is so important: for example the standard metrics page describes how we define “MAU” and “DAU”: these are measures that we want to standardize in the organization, and not have someone re-invent every time they produce an analysis or report. However, we should be very cautious about how much of this “front facing” material we include: if we overwhelm our audience with details right out of the gate, they are apt to ignore them.
Concrete actions
- We should continue working on tutorials on how to perform common tasks: this includes not only the low-level guides that we currently have (e.g. BigQuery and SQL tutorials) but also information on how to effectively use our higher-level, more accessible tools like GLAM and GUD to answer questions.
- Medium term, we should remove the per-dataset documentation and replace it with a graphical tool for browsing this type of information (perhaps Google Data Catalog). Since this is likely to be a rather involved project, we can keep the existing documentation for now — but for new datasets, we should encourage their authors to write tutorials on how to use them effectively (assuming they are of broad general interest) instead of hand-creating schema definitions that are likely to go out of date quickly.
- We should set clear expectations and guidelines of what does and doesn’t belong on docs.telemetry.mozilla.org as part of a larger style guide. This style guide should be referenced somewhere prominent (perhaps as part of a pull request template) so that historical knowledge of what this resource is for isn’t lost.
Footnotes
-
For some reason which I cannot fathom, a broad (non-Mozilla) audience seems unusually interested in our SQL style guide. ↩
-
The current Firefox data documentation has a project glossary that is riddled with links to obsolete and unused projects. ↩
-
docs.telemetry.mozilla.org has a huge section devoted to derived datasets (20+), many of which are obsolete or not recommended. At the same time, we are missing explicit reference material for the most commonly used tables in BigQuery (e.g.
telemetry.main). ↩