Herding Automation Infrastructure
Aug 17th, 2016
For every commit to Firefox, we run a battery of builds and automated tests on the resulting source tree to make sure that the result still works and meets our correctness and performance quality criteria. This is expensive: every new push to our repository implies hundreds of hours of machine time. However, automated quality control is essential to ensure that the product that we’re shipping to users is something that we can be proud of.
But what about evaluating the quality of the product which does the building and testing? Who does that? And by what criteria would we say that our automation system is good or bad? Up to now, our procedures for this have been rather embarassingly adhoc. With some exceptions (such as OrangeFactor), our QA process amounts to motivated engineers doing a one-off analysis of a particular piece of the system, filing a few bugs, then forgetting about it. Occasionally someone will propose turning build and test automation for a specific platform on or off in mozilla.dev.planning.
I’d like to suggest that the time has come to take a more systemic approach to this class of problem. We spend a lot of money on people and machines to maintain this infrastructure, and I think we need a more disciplined approach to make sure that we are getting good value for that investment.
As a starting point, I feel like we need to pay closer attention to the following characteristics of our automation:
- End-to-end times from push submission to full completion of all build and test jobs: if this gets too long, it makes the lives of all sorts of people painful — tree closures become longer when they happen (because it takes longer to either notice bustage or find out that it’s fixed), developers have to wait longer for try pushes (making them more likely to just push directly to an integration branch, causing the former problem…)
- Number of machine hours consumed by the different types of test jobs: our resources are large (relatively speaking), but not unlimited. We need proper accounting of where we’re spending money and time. In some cases, resources used to perform a task that we don’t care that much about could be redeployed towards an underresourced task that we do care about. A good example of this was linux32 talos (performance tests) last year: when the question was raised of why we were doing performance testing on this specific platform (in addition to Linux64), no one could come up with a great justification. So we turned the tests off and reconfigured the machines to do Windows performance tests (where we were suffering from a severe lack of capacity).
Over the past week, I’ve been prototyping a project I’ve been calling “Infraherder” which uses the data inside Treeherder’s job database to try to answer these questions (and maybe some others that I haven’t thought of yet). You can see a hacky version of it on my github fork.
Why implement this in Treeherder you might ask? Two reasons. First, Treeherder already stores the job data in a historical archive that’s easy to query (using SQL). Using this directly makes sense over creating a new data store. Second, Treeherder provides a useful set of front-end components with which to build a UI with which to visualize this information. I actually did my initial prototyping inside an ipython notebook, but it quickly became obvious that for my results to be useful to others at Mozilla we needed some kind of real dashboard that people could dig into.
On the Treeherder team at Mozilla, we’ve found the New Relic software to be invaluable for diagnosing and fixing quality and performance problems for Treeherder itself, so I took some inspiration from it (unfortunately the problem space of our automation is not quite the same as that of a web application, so we can’t just use New Relic directly).
There are currently two views in the prototype, a “last finished” view and a “total” view. I’ll describe each of them in turn.
Last finished
This view shows the counts of which scheduled automation jobs were the “last” to finish. The hypothesis is that jobs that are frequently last indicate blockers to developer productivity, as they are the “long pole” in being able to determine if a push is good or bad.
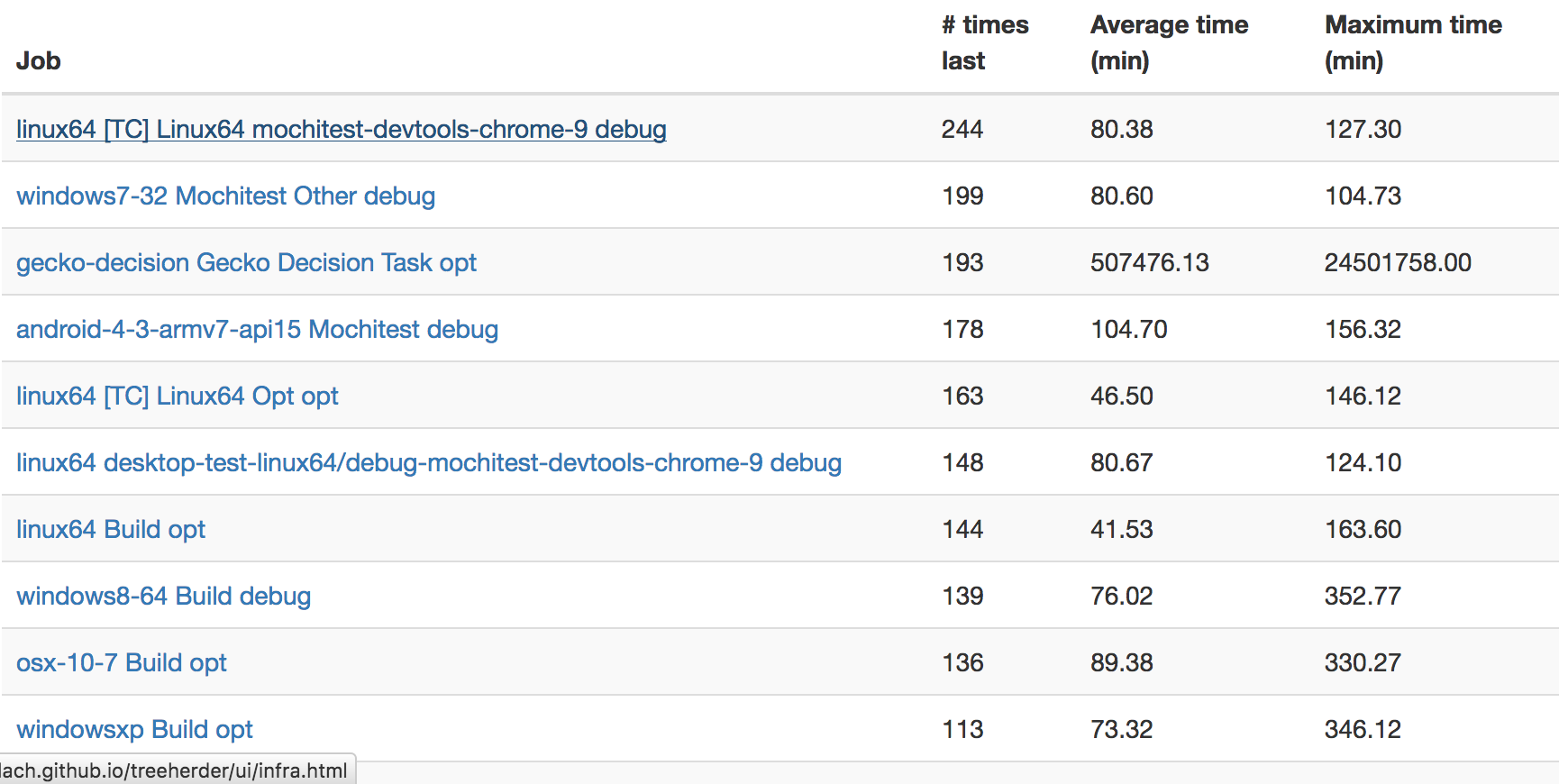
Right away from this view, you can see the mochitest devtools 9 test is often the last to finish on try, with Windows 7 mochitest debug a close second. Assuming that the reasons for this are not resource starvation (they don’t appear to be), we could probably get results into the hands of developers and sheriffs faster if we split these jobs into two seperate ones. I filed bugs 1294489 and 1294706 to address these issues.
Total Time
This view just shows which jobs are taking up the most machine hours.
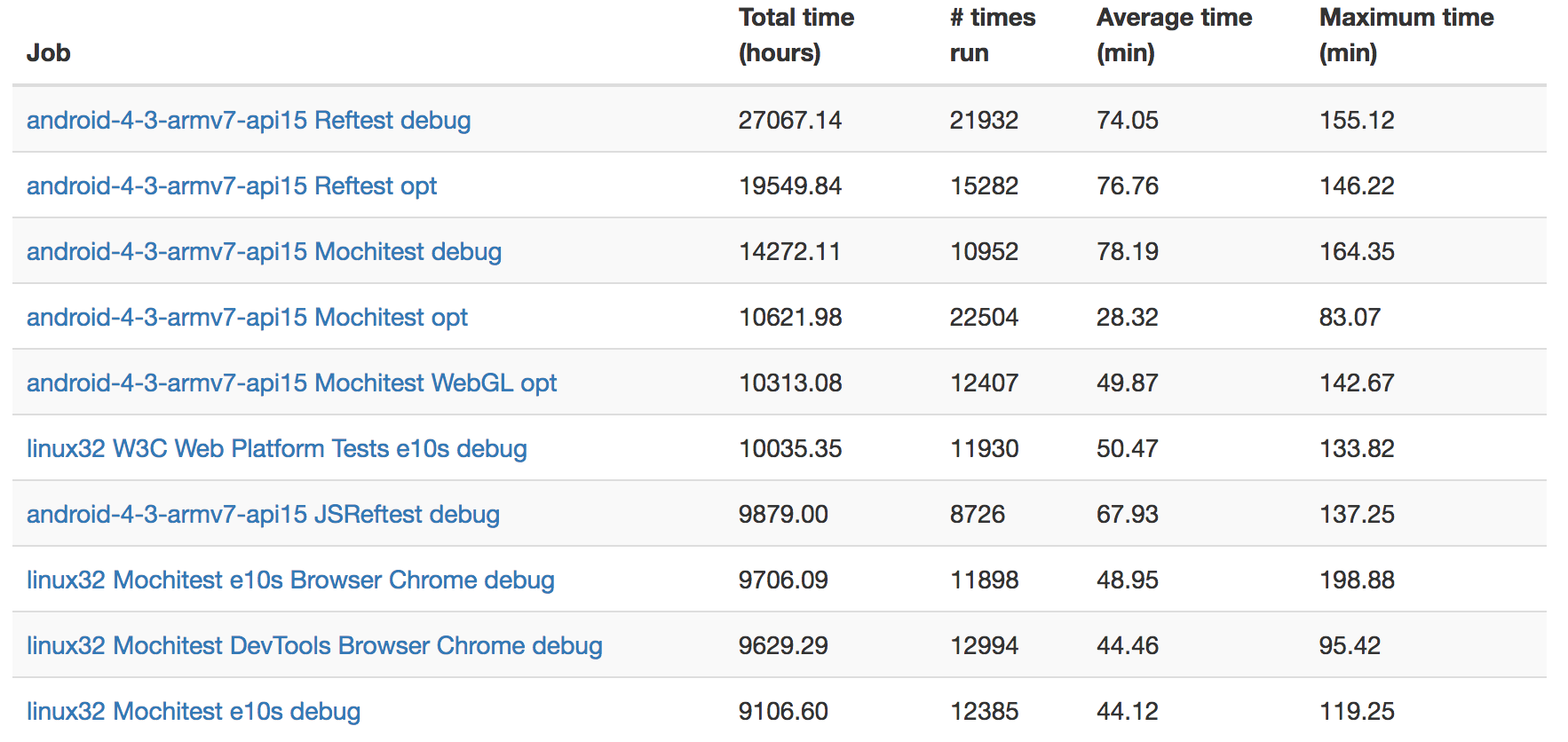
Probably unsurprisingly, it seems like it’s Android test jobs that are taking up most of the time here: these tests are running on multiple layers of emulation (AWS instances to emulate Linux hardware, then the already slow QEMU-based Android simulator) so are not expected to have fast runtime. I wonder if it might not be worth considering running these tests on faster instances and/or bare metal machines.
Linux32 debug tests seem to be another large consumer of resources. Market conditions make turning these tests off altogether a non-starter (see bug 1255890), but how much value do we really derive from running the debug version of linux32 through automation (given that we’re already doing the same for 64-bit Linux)?
Request for comments
I’ve created an RFC for this project on Google Docs, as a sort of test case for a new process we’re thinking of using in Engineering Productivity for these sorts of projects. If you have any questions or comments, I’d love to hear them! My perspective on this vast problem space is limited, so I’m sure there are things that I’m missing.