Better or worse: by what measure?
Oct 26th, 2017
Ok, after a series of posts extolling the virtues of my current project, it’s time to take a more critical look at some of its current limitations, and what we might do about them. In my introductory post, I talked about how Mission Control can let us know how “crashy” a new release is, within a short interval of it being released. I also alluded to the fact that things appear considerably worse when something first goes out, though I didn’t go into a lot of detail about how and why that happens.
It just so happens that a new point release (56.0.2) just went out, so it’s a perfect opportunity to revisit this issue. Let’s take a look at what the graphs are saying (each of the images is also a link to the dashboard where they were generated):
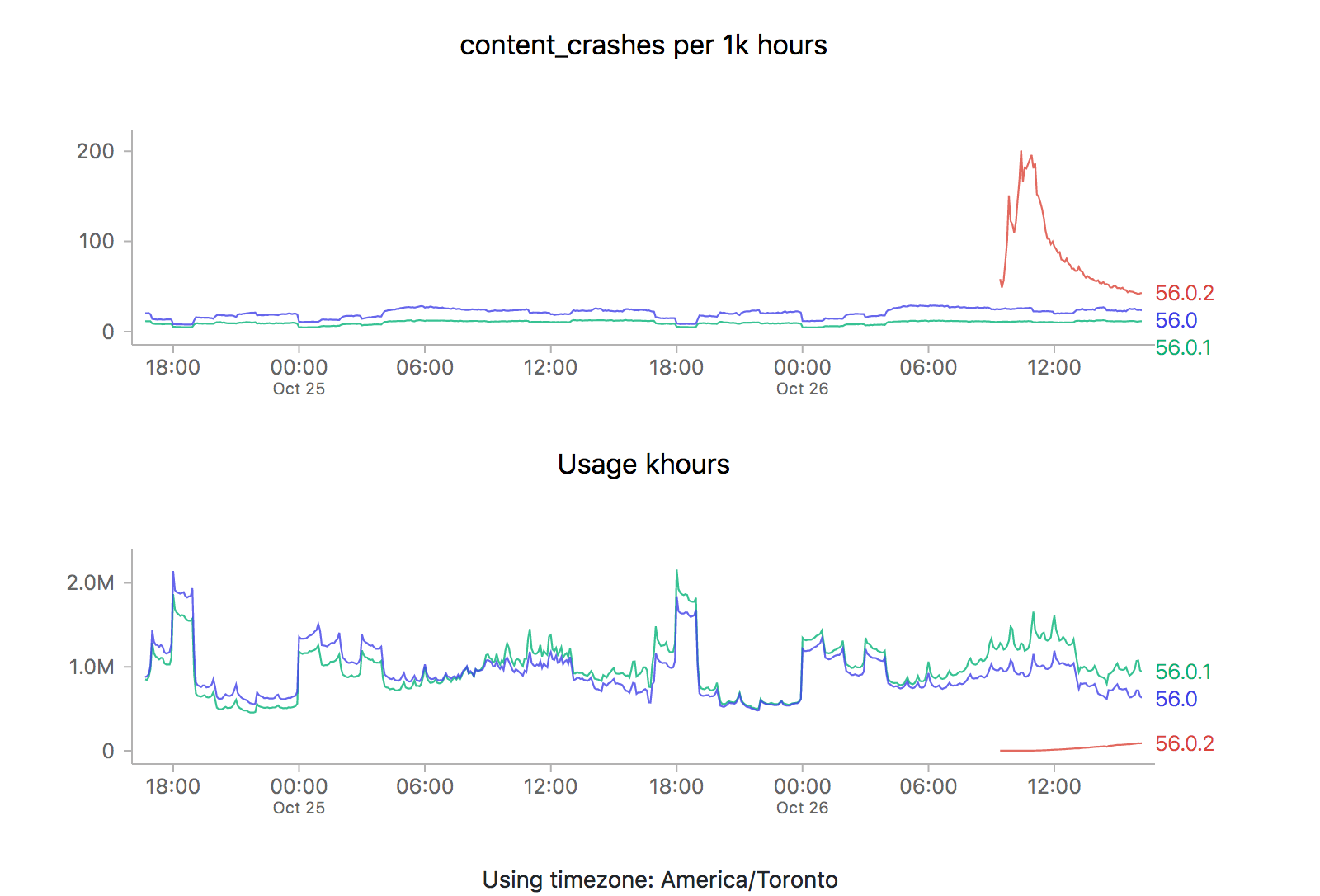
ZOMG! It looks like 56.0.2 is off the charts relative to the two previous releases (56.0 and 56.0.1). Is it time to sound the alarm? Mission control abort? Well, let’s see what happens the last time we rolled something new out, say 56.0.1:
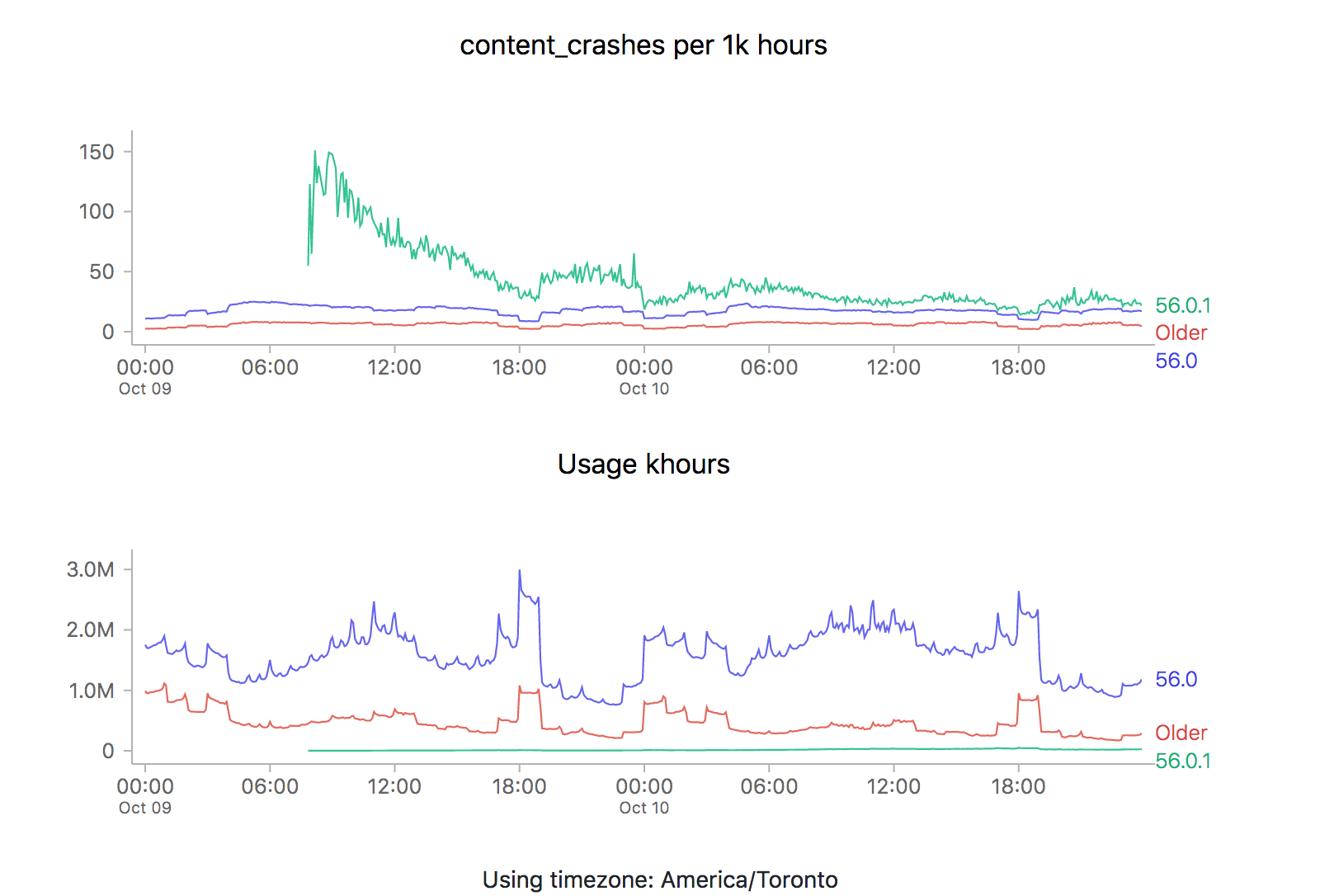
We see the exact same pattern. Hmm. How about 56.0?
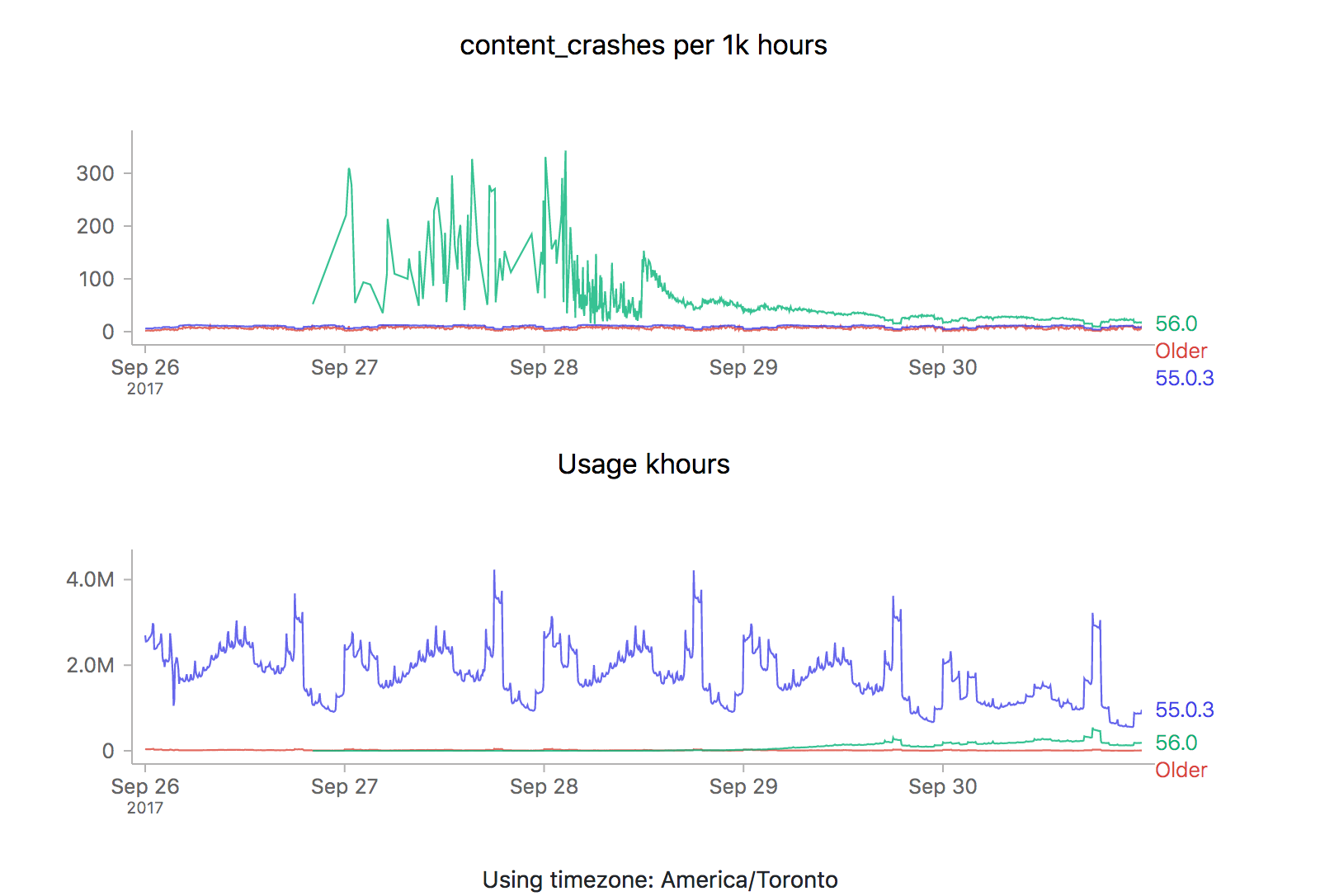
Yep, same pattern here too (actually slightly worse).
What could be going on? Let’s start by reviewing what these time series graphs are based on. Each point on the graph represents the number of crashes reported by telemetry “main” pings corresponding to that channel/version/platform within a five minute interval, divided by the number of usage hours (how long users have had Firefox open) also reported in that interval. A main ping is submitted under a few circumstances:
- The user shuts down Firefox
- It’s been about 24 hours since the last time we sent a main ping.
- The user starts Firefox after Firefox failed to start properly
- The user changes something about Firefox’s environment (adds an addon, flips a user preference)
A high crash rate either means a larger number of crashes over the same number of usage hours, or a lower number of usage hours over the same number of crashes. There are several likely explanations for why we might see this type of crashy behaviour immediately after a new release:
- A Firefox update is applied after the user restarts their browser for any reason, including their browser crash. Thus a user whose browser crashes a lot (for any reason), is more prone to update to the latest version sooner than a user that doesn’t crash as much.
- Inherently, any crash data submitted to telemetry after a new version is released will have a low number of usage hours attached, because the client would not have had a chance to use it much (because it’s so new).
Assuming that we’re reasonably satisfied with the above explanation, there’s a few things we could try to do to correct for this situation when implementing an “alerting” system for mission control (the next item on my todo list for this project):
- Set “error” thresholds for each crash measure sufficiently high that we don’t consider these high initial values an error (i.e. only alert if there is are 500 crashes per 1k hours).
- Only trigger an error threshold when some kind of minimum quantity of usage hours has been observed (this has the disadvantage of potentially obscuring a serious problem until a large percentage of the user population is affected by it).
- Come up with some expected range of what we expect a value to be for when a new version of firefox is first released and ratchet that down as time goes on (according to some kind of model of our previous expectations).
The initial specification for this project called for just using raw thresholds for these measures (discounting usage hours), but I’m becoming increasingly convinced that won’t cut it. I’m not a quality control expert, but 500 crashes for 1k hours of use sounds completely unacceptable if we’re measuring things at all accurately (which I believe we are given a sufficient period of time). At the same time, generating 20–30 “alerts” every time a new release went out wouldn’t particularly helpful either. Once again, we’re going to have to do this the hard way…
—
If this sounds interesting and you have some react/d3/data visualization skills (or would like to gain some), learn about contributing to mission control.
Shout out to chutten for reviewing this post and providing feedback and additions.