Irydium: Points of departure
Jun 28th, 2021
So it’s my first day at the Recurse centre, which I blogged briefly about last week. I thought I’d start out by going into a bit more detail about what I’m trying to do with Irydium. This post might be a bit discursive and some of my thoughts are only half-formed: my intent here is towards trying to express some of these ideas at all rather than to come up with the perfect formulation for them, which is going to take time. It is based partly on a presentation I gave at Mozilla last Friday (just before going on my 6-week leave, which starts today).
First principles
The premise of Irydium is that despite obvious advances in terms of the ability of computers to crunch numbers and analyze data, our ability to share whatever we learn from these understandings is still far too difficult, especially for people new to the field. Even for domain experts (those with the job title “Data Engineer” or “Data Scientist” or similar) this is still more difficult than one would like.
I’ve made a few observations over the past couple years of trying to explain and document Mozilla’s data platform that I think form a good starting point for trying to close the gap:
- Text is pretty great. Writing, just plain text, is (in my opinion) the single best medium for giving context to data. In terms of raw information density and ability to communicate complex ideas, nothing beats it. If you haven’t read it before, the essay always bet on text (by Graydon Hoare, creator of Rust) is well worth reading.
- Markdown is pretty great too. Essentially an easy-to-write superset of HTML, it’s become the medium of choice for many desktop publishing workflows and has become the basis for many efforts in the “interactive presentation” space that I’m most interested in.
- Reactive Systems make Data Exposition Exposition Easier. A reactive abstraction in front of your computational model reduces development times, makes your work more reproducible and is often easier for less-experienced people to understand. I’d cite the long-standing success of Excel and the recent interest in projects like Observable as evidence for this.
Ok, so what is Irydium?
Irydium is, at heart, a way to translate markdown documents into an interactive, compelling visual presentation.
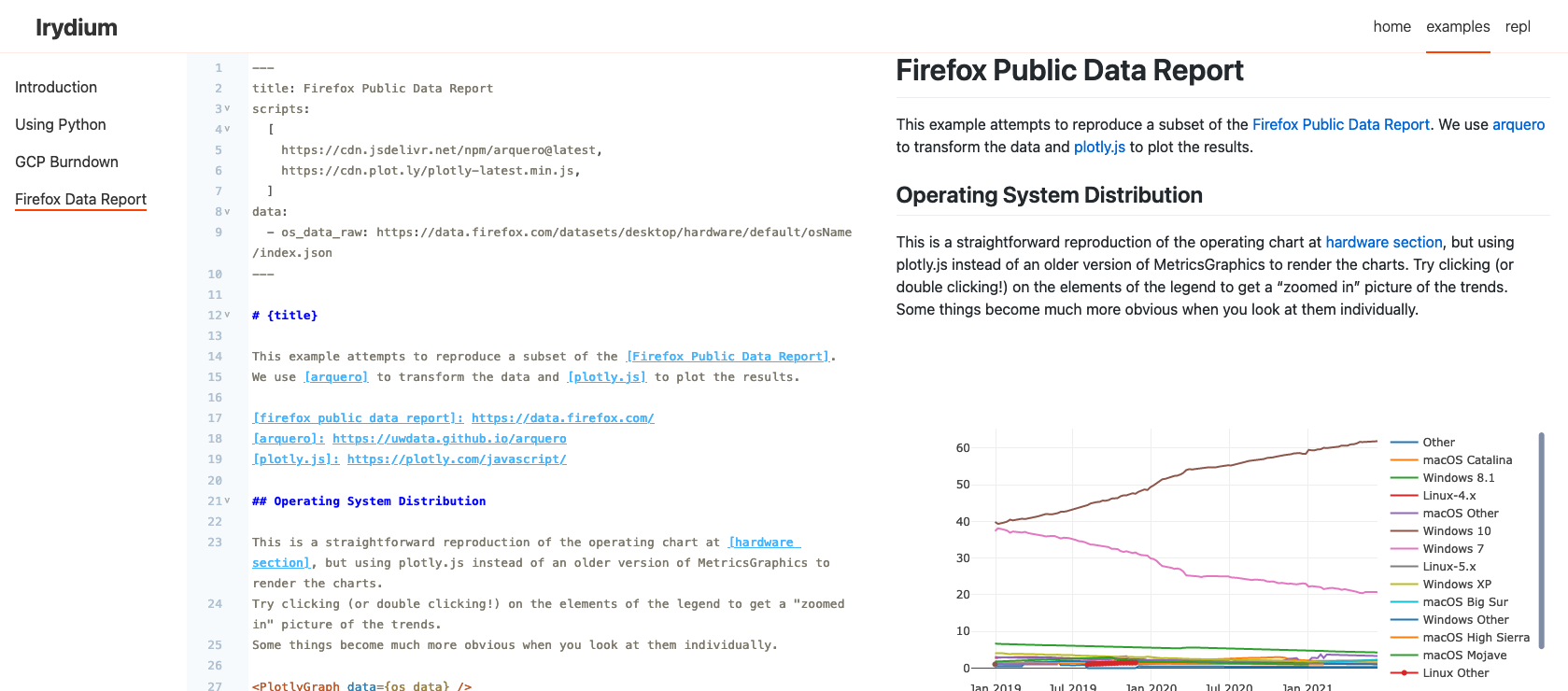
My view is that publishing markdown text on the web is very close to a solved problem, and that we should build on that success rather than invent something new. This is not necessarily a new point of view (e.g. Rmarkdown and JupyterBook have similar premises) but I think some aspects of Irydium’s approach are mildly novel (or at least within the space of “not generally accepted ideas”).
If you want to get a bit of a flavor for how it works, visit the demonstration site (irydium.dev) and play with some of the examples.
What makes Irydium different from <X>?
While there are a bunch of related projects in this space, there’s a few design principles about Irydium that make it a little different from most of what’s already out there1:
- Reactive: Irydium is reactive in the same way that a spreadsheet is — that is, any individual change you make will immediately flow to the rest of the system. This provides a more intuitive model for the creator of the document and also makes it easier to create truly interactive visualizations.
- Idempotent: in Irydium, a source document will yield the same presentation every time it’s run. There’s no need to reason about what the state of the “kernel” is. This is a highly valuable property when thinking about how to make your analyses reproducible.
- Familiar: Irydium uses as few novel concepts and technologies as possible: it builds on some of the best ideas and technologies produced by the open source community: Python, pyodide, Svelte, mdsvex, MyST and a few others — chosen for having a reasonably shallow learning curve.
- Hackable: While I’m working on an online environment to build and share irydium documents, it’s also fully possible to do so using the tools you know and love like Visual Studio Code.
Related projects
With the above caveats, there are still a number of projects that overlap with Irydium’s ideas and/or design goals. A few that seem worth mentioning here:
- Iodide: This is the obvious one, at least for those who have been following my work for a while. Iodide was an experiment in making a “web native” version of a scientific notebook: it uses the cell-based computational model that will be familiar to anyone who’s used Jupyter, but all the computation happens on the client. It is probably most famous for launching pyodide, a port of Python to WebAssembly (that Irydium now uses to support Python). I feel like it has a number of design issues (some of which I’ve blogged about previously) and is not currently in active development.
- Observable: Client-side reactive notebooks, commercial backing, broadly used in the D3 community. Shares Irydium’s reactive approach, departs from it in terms of using a custom file format and emphasizing their interactive editing and collaboration environment (which is indeed quite impressive). I’ve used Observable for a few small work things (example) and while there’s a lot I like about it, I am a bit non-plussed by how many wheels it reinvents and the implicit lock-in to a single vendor.2
- Starboard: Similar in some ways to Iodide, but in active development. I’ve started chatting a bit with the core developers on whether there might be areas we could collaborate.
- Ellx: I found out a bit about this relatively recently, via the Svelte discord. Actually very close in some ways to Irydium in terms of choices of technology (e.g. Svelte). Again, in initial chats with the core developers on possible collaborations.
Success criteria
My intent with Irydium, at this point in its development, is to prove out some concepts and see where they lead. While I’d welcome it if Irydium became a successful, widely adopted environment for building interactive data visualizations, I’d also be totally happy with other outcomes, such as:
- Providing a source of ideas and/or code for other people.
- Working on (or with) Irydium being a good learning experience both for myself and others
-
Please don’t conflate “unique” with “superior”: I’m well aware that all designs come with trade offs. In particular, Irydium’s approach will almost certainly make it difficult / impossible to directly interact with “big data” systems in an efficient way. ↩
-
There is at least one effort (Dataflow) to allow editing Observable documents without using Observable itself, which is interesting. ↩