Getting back into the swing of things at Mozilla after my extended break. I’m currently working on enhancing and extending Looker support for Glean-based applications, which eventually led me back to working on bigquery-etl, our framework for creating derived datasets in our data lake.
I spent some time working on improving the initial developer experience of bigquery-etl early this year, so I figured it would be no problem to get going again despite an extended hiatus from it (I think it’s probably been ~2–3 months since I last touched it). Unfortunately the first thing I got after creating a fresh virtual environment (to pick up the new dependency updates) was this exciting looking error:
wlach@antwerp bigquery-etl % ./bqetl --help
Traceback (most recent call last):
...
File "/Users/wlach/src/bigquery-etl/venv/lib/python3.9/site-packages/google/cloud/bigquery_v2/types/__init__.py", line 16, in <module>
from .encryption_config import EncryptionConfiguration
File "/Users/wlach/src/bigquery-etl/venv/lib/python3.9/site-packages/google/cloud/bigquery_v2/types/encryption_config.py", line 26, in <module>
class EncryptionConfiguration(proto.Message):
File "/Users/wlach/src/bigquery-etl/venv/lib/python3.9/site-packages/proto/message.py", line 200, in __new__
file_info = _file_info._FileInfo.maybe_add_descriptor(filename, package)
File "/Users/wlach/src/bigquery-etl/venv/lib/python3.9/site-packages/proto/_file_info.py", line 42, in maybe_add_descriptor
descriptor=descriptor_pb2.FileDescriptorProto(
TypeError: descriptor to field 'google.protobuf.FileDescriptorProto.name' doesn't apply to 'FileDescriptorProto' object
What I did
Since we have pretty decent continuous integration at Mozilla, when I see an error like this I am usually pretty sure it’s some kind of strange interaction between my local development environment and whatever dependencies we’ve specified for the repository in question. Usually these problems are pretty easy to solve.
First thing I tried was to type the error into Google, to see if this had come up for anyone else before. I tried several variations of TypeError: descriptor to field and FileDescriptorProto and nothing really turned up. This strategy almost always turns up something. When it doesn’t it usually indicates that something pretty strange is happening.
To see if this was a strange problem particular to us, I asked on our internal channel but no one had offhand seen or heard of this error either. One of my colleagues (who had a working setup on a Mac, the same environment I was using) suggested I set up pyenv to isolate my development environment, which was a good idea but did not seem to solve the problem: both Python 3.8 and 3.9 installed via pyenv ran into the exact same issue.
After flailing around trying a number of other failed approaches (maybe I need to upgrade the version of virtualenv that we’re using?), I broke down and looked harder at the error itself. It seemed to be some kind of typing error in Google’s protobuf library, which google-cloud-bigquery is calling. If this sort of thing was happening to everyone, we probably would have seen it happening more broadly. So my guess, again, was that it was happening due to an obscure interaction between some variable on my machine and this particular combination of dependencies.
At this point, I systematically went through our set of python dependencies to see what might be the matter. For the most part, I found nothing surprising or suspicious. google-api-core was at the latest version, as was google-cloud-bigquery. However, I did notice that the version of protobuf we were using was a little older (3.15.8 when the latest “official” version on pypi was 3.17.3).
It seemed like a longshot that the problem was there, but it seemed like upgrading the dependency was worth a try just in case. So I bumped the version of protobuf to the latest version in my local checkout (pip install protobuf==3.17.3)…
… and sure enough, after doing so, the problem was fixed and ./bqetl --help started working again:
wlach@antwerp bigquery-etl % ./bqetl --help
Usage: bqetl [OPTIONS] COMMAND [ARGS]...
CLI tools for working with bigquery-etl.
...
After doing so, I did up a quick pull request and the problem is now fixed, at least for me.
It’s a bit unfortunate that dependabot (which we have configured for this repository) didn’t send an update for protobuf, which would have fixed this problem earlier.1 It seems like it’s not completely reliable for python packages, for whatever reason: I have also noticed this problem with mozregression.
I suspect (though can’t confirm) that the problem here is a backwards-incompatible change made to either protobuf or one of the packages that uses it. However, the nature of the incompatibility seems subtle: bigquery-etl works fine with the old set of dependencies we run in continuous integration and it appears to only come up in specific circumstances (i.e. mine). Unfortunately, I need to get back to what I was actually planning to work on and don’t have time to unwind the rather set of complex interactions going on here. Maybe later!
What I would have done differently
This kind of illustrates (again) to me that while some shortcuts and heuristics can save a bunch of time and mental effort (Googling things all the time is basically standard practice in the industry at this point), sometimes you really just need to start a little closer at the problem to find a solution. I was hesitant to do this in this case because I’m never sure where those kinds of rabbit holes are going to take me (e.g. I spent several days debugging a bad interaction between Kubernetes and our airflow cluster in late 2019 with not much to show for the effort), but often all it takes is understanding the general shape of the problem to move you to a quick solution.
Other lessons
Here’s a couple of other things this experience reinforced for me (these are more subjective, take them or leave them):
Local development environments are kind of a waste of time. The above work took me several hours and it’s going to result in ~zero user-visible improvements for anyone outside of Mozilla Data Engineering. I’m excited about the potential productivity improvements that might come from using tools like GitHub Codespaces.
While I can’t confirm this was the source of the problem in this particular case, in general backwards compatibility on every level is super important when your software has broad reach and doubly so if it’s a widely-used dependency of other software (and is thus hard to reason about in isolation). In these cases, what seems like a trivial change (e.g. improving the type signatures inside a Python library) can squander many hours of people’s time if you’re not careful. Backwards-incompatible changes, however innocuous they may seem, should always invoke a major version bump.
Likewise, bugs in software that have broad usage (like dependabot) can have big downstream impacts. If dependabot’s version bumping for python was more reliable, we likely wouldn’t have had this problem. The glass-half-full interpretation of this is that fixing these types of issues would have an outsized benefit for the commons.
As an aside, the main reason we use dependabot and aggressively update packages like google-api-core is due to a bug in pip. ↩
Went to PyData NYC a couple weeks ago, and figured I ought to write up my thoughts for the benefits of the others on my extended team. Why not publish as a blog post while I’m at it?
This is actually the first conference I’d been to in my capacity as a “data engineer” at Mozilla, a team I joined about a year and a half ago after specializing in the same area on the (now-defunct) a-team. I’ve felt a special affinity for the Python community, particularly its data science offshoots (pandas, numpy, and jupyter notebooks) so it was great to finally go to a conference that specializes in these topics.
Overall, the conference was a bit of a mix between people talking about the status of their projects, theoretical talks on specific statistical approaches to data, general talks on how people are doing “data science” (I would say the largest majority of attendees at the conference were users of python data science tools, rather than developers), and case studies of how people are using python data science tools in their research or work. This being New York, many (probably the majority) were using data science tools in fields like quantitative finance, sales, marketing, and health care.
As a side note, it was really satisfying to be able to tell Mozilla’s story about how we collect and use data without violating the privacy of our users. This is becoming more and more of an issue (especailly in Europe with the GPDR) and it really makes me happy that we have a really positive story to tell, not a bunch of dirty secrets that we need to hide.
In general I found the last two types of talks the most rewarding to go to: most of the work I do at Mozilla currently involves larger-scale data where, I’m sad to say, Python is usually not (currently) an applicable tool, at least not by itself (though maybe iodide will help change that! see below). And I don’t usually find a 60 minute talk really enough time for me to be able to properly absorb new mathematical or statistical concepts, though I can sometimes get little tidbits of information from them that come in handy later.
Some talks that made an impression on me:
Open source and quantitative finance: Keynote talk, was a great introduction to the paranoia of the world of quantitative finance. I think the main message was that things are gradually moving to a (slightly less) paranoid model where generally-useful modifications done to numerical/ml software as part of a trading platform may now be upstreamed… but my main takeaway is that I’m really glad I’m not working in that industry.
Words in Space: Introduced an interesting-soundingl library called Yellow Brick for visualizing the results of machine learning models.
Creating a data-driven product culture: General talk on how to create a positive and useful data science culture at a company. I think Mozilla already checks most of the boxes outlined in the talk.
What Data Scientists Really Do: Quite entertaining talk on the future of “data science”, by Hugo Bowne-Anderson (who also has a podcast which sounds cool). The most interesting takeaway from the talk was the speculation that within 10 years the term “data scientist” might have the same meaning as the word “webmaster” now. It’s a hyper-generalist job description which will almost inevitably be split into a number of other more specialized roles.
Master Class: Bayesian Statistics: This falls under the “technical talk which I couldn’t grasp in 60 minutes” category, but I think I finally do understand a little bit more of what people mean when they say “Bayesian Statistics” now. It actually doesn’t have much to do with Baye’s Theorem, rather it seems to be more of a philosophical approach to data analysis which acknowledges the limitations of human capacity to understand the world and asks us to more explicitly state our assumptions when developing models (probably over-simplifying here). I think I can get behind that — want to learn more. They provided a bunch of material to work through, which I’ve been meaning to take a look at.
Data Science in Health Care: Beyond the Hype: Great presentations in how data science can be used to improve health care outcomes. Lots of relevant insights that I think are also applicable to “product health” here at Mozilla. I particularly liked the way the presenter framed requirements when deciding whether or not to do a type of analysis: “if i knew [information], i would do [intervention], which would have [measurable outcome]”
Of course, this post wouldn’t be complete without a mention of Mike Droettboom’s talk on iodide, a project I’ve been spending some considerable cycles helping with over the last couple of quarters. I need to write some longer thoughts on iodide at some point in the near future, but in a nutshell it’s a scientific notebook environment where the computational kernel lives entirely inside the browser. It was well received and we had a great followup session afterwards with people interested in using it for various things. Being able to show a python environment in the browser which “just works”, with no installation or other steps makes a great tech demo. I’m really excited about the public launch of our server-based environment, which will hopefully be coming in the next couple of months.
So I went to PyCon 2015. While I didn’t leave quite as inspired as I did in 2014 (when I discovered iPython), it was a great experience and I learned a ton. Once again, I was incredibly impressed with the organization of the conference and the diversity and quality of the speakers.
Since Mozilla was nice enough to sponsor my attendance, I figured I should do another round up of notable talks that I went to.
Technical stuff that was directly relevant to what I work on:
To ORM or not to ORM (Christine Spang): Useful talk on when using a database ORM (object relational manager) can be helpful and even faster than using a database directly. I feel like there’s a lot of misinformation and FUD on this topic, so this was refreshing to see. videoslides
Debugging hard problems (Alex Gaynor): Exactly what it says — how to figure out what’s going on when things aren’t behaving as they should. Great advice and wisdom in this one (hint: take nothing for granted, dive into the source of everything you’re using!). videoslides
Python Performance Profiling: The Guts And The Glory (Jesse Jiryu Davis): Quite an entertaining talk on how to properly profile python code. I really liked his systematic and realistic approach — which also discussed the thought process behind how to do this (hint: again it comes down to understanding what’s really going on). Unfortunately the video is truncated, but even the first few minutes are useful. video
Non-technical stuff:
The Ethical Consequences Of Our Collective Activities (Glyph): A talk on the ethical implications of how our software is used. I feel like this is an under-discussed topic — how can we know that the results of our activity (programming) serves others and does not harm? video
How our engineering environments are killing diversity (and how we can fix it) (Kate Heddleston): This was a great talk on how to make the environments in which we develop more welcoming to under-represented groups (women, minorities, etc.). This is something I’ve been thinking a bunch about lately, especially in the context of expanding the community of people working on our projects in Automation & Tools. The talk had some particularly useful advice (to me, anyway) on giving feedback. videoslides
I probably missed out on a bunch of interesting things. If you also went to PyCon, please feel free to add links to your favorite talks in the comments!
Just wanted to give some quick updates on mozregression, your favorite regression-finding tool for Firefox:
I moved all issue tracking in mozregression to bugzilla from github issues. Github unfortunately doesn’t really scale to handle notifications sensibly when you’re part of a large organization like Mozilla, which meant many problems were flying past me unseen. File your new bugs in bugzilla, they’re now much more likely to be acted upon.
Sam Garrett has stepped up to be co-maintainer of the project with me. He’s been doing a great job whacking out a bunch of bugs and keeping things running reliably, and it was time to give him some recognition and power to keep things moving forward.
On that note, I just released mozregression 0.17, which now shows the revision number when running a build (a request from the graphics team, bug 1007238) and handles respins of nightly builds correctly (bug 1000422). Both of these were fixed by Sam.
If you’re interested in contributing to Mozilla and are somewhat familiar with python, mozregression is a great place to start. The codebase is quite approachable and the impact will be high — as I’ve found out over the last few months, people all over the Mozilla organization (managers, developers, QA) use it in the course of their work and it saves tons of their time. A list of currently open bugs is here.
This year’s PyCon US (Python Conference) was in my city of residence (Montréal) so I took the opportunity to go and see what was up in the world of the language I use the most at Mozilla. It was pretty great!
ipython
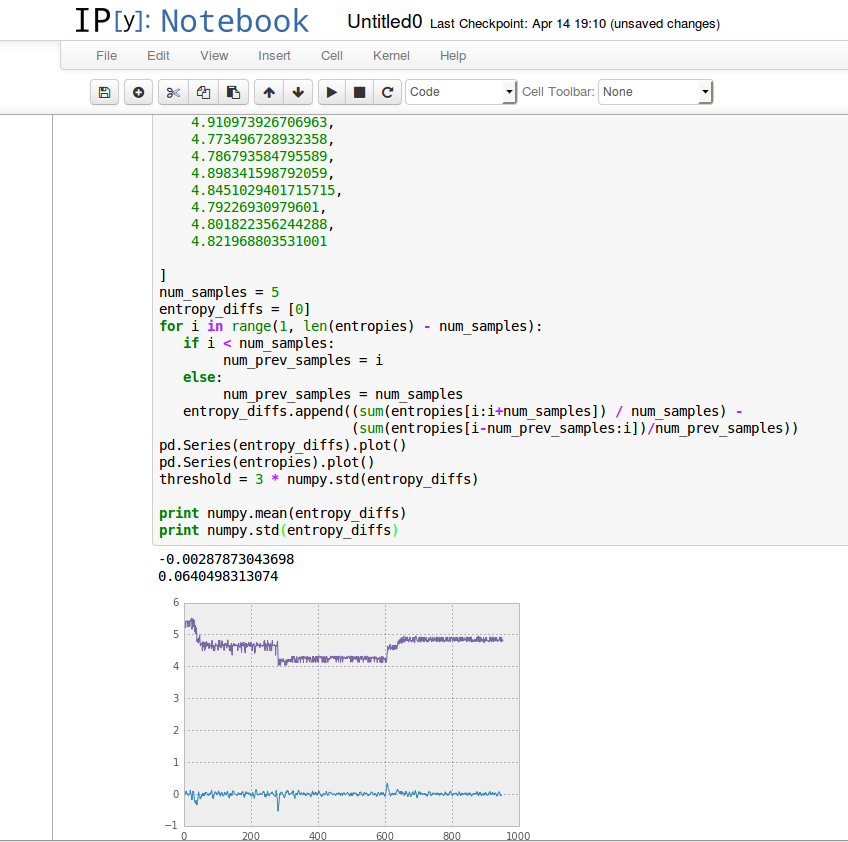
The highlight for me was learning about the possibilities of ipython notebooks, an absolutely fantastic interactive tool for debugging python in a live browser-based environment. I’d heard about it before, but it wasn’t immediately apparent how it would really improve things — it seemed to be just a less convenient interface to the python console that required me to futz around with my web browser. Watching a few presentations on the topic made me realize how wrong I was. It’s already changed the way I do work with Eideticker data, for the better.
[][3]
Using ipython to analyze some eideticker data
I think the basic premise is really quite simple: a better interface for typing in, experimenting with, and running python code. If you stop and think about it, the modern web interface supports a much richer vocabulary of interactive concepts that the console (or even text editors like emacs): there’s no reason we shouldn’t take advantage of it.
Here are the (IMO) killer features that make it worth using:
The ability to immediately re-execute a block of code after editing and seeing an error (essentially merging the immediacy of the python console with the permanency / cut & pastability of an actual script)
Live-printing out graphs of numerical results using matplotlib. ZOMG this is so handy. Especially in conjunction with the live-editing outlined above, there’s no better tool for fine-tuning mathematical/statistical analysis.
The shareability of the results. Any ipython notebook can be saved and then saved to a public website. Many presentations at PyCon 2014, in fact, were done entirely with ipython notebooks. So handy for answering questions like “how did you get that”?
I saw some other good talks at the conference, here are some of them:
All Your Ducks In A Row: Data Structures in the Standard Library and Beyond : A useful talk by Brandon Rhoades on the implementation of basic data structures in Python, and how to select the ones to use for optimal performance. It turns out that lists aren’t the best thing to use for long sequences of numerical data (who knew?)
Fast Python, Slow Python : An interesting talk by Alex Gaynor about how to write decent performing pure-python code in a single-threaded context. Lots of intelligent stuff about producing robust code that matches your intention and data structures, and caution against doing fancy things in the name of being “pythonic” or “general”.
Analyzing Rap Lyrics with Python : Another data analysis talk, this one about a subject I knew almost nothing about. The best part of it (for me anyway) was learning how the speaker (Julie Lavoie) narrowed her focus in her research to the exact aspects of the problem that would let her answer the question she was interested in (“Can we automatically find out which rap lyrics are the most sexist?”) as opposed to interesting problems (“how can I design the most general scraping library possible?”) that don’t answer the question. In my opinion, this ability to focus is one of the key things that seperates successful projects from unsuccessful ones.
Just a few quick notes on how to avoid a class of errors I’ve been seeing in Mozilla’s automation over the last year. Since python interprets code dynamically, it’s pretty easy for problems like undefined variables to slip through, especially if they’re in a codepath that isn’t frequently tested. The most recent example I found was in some cleanup-after-error code for remote mochitest/reftest, which tried to call “self.cleanup” from a standalone method.
We’re calling cleanup as if it were a class variable, but we’re not inside any class! It’s easy to see what will happen if you try to run some similar code from the python console:
>>> self.cleanup()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'self' is not defined
However, because we’re in a blanket try…except, we will never see an error. The cleanup code will never be called, instead the exception is immediately caught and subsequently ignored. Probably not the end of the world in this case (there are other parts of our mobile automation which will perform the same cleanup later), but it’s easy to imagine where this would be a more serious problem.
There’s two very easy ways to help stop errors like this before they hit our code:
Try to avoid using a blanket try…except. In addition to catching legitimate problems which we want to ignore (in the remote case for example, devicemanager exceptions), it also catches (and thus obscures) things like syntax, name, or type errors. Instead, try just catching the specific exception you’re looking for. For example, we might rewrite the case above as:
2. pyflakes, pyflakes, pyflakes. [Pyflakes][2] is a fantastic tool for analyzing your python code for common problems. It's kind of analagous to [jslint][3], for those of you familiar with that. Here's what happens when we run pyflakes against the offending code:
```
wlach@eideticker:~/src/mozilla-central$ pyflakes testing/mochitest/runtestsremote.py
testing/mochitest/runtestsremote.py:7: 'time' imported but unused
testing/mochitest/runtestsremote.py:481: undefined name 'self'
testing/mochitest/runtestsremote.py:500: undefined name 'self'
I've found pyflakes to be an indispensable part of my workflow. I generally run it after making any substantial change to a python file, and certainly before pushing anything to be consumed by others.
Ultimately there’s no substitute for actually thoroughly testing your code, no matter what language you’re using. But using the right techniques and tools can certainly make your life easier.
[ for those wondering, a fix for the issue mentioned in this post is part of bug 801652 ]
 ][3]
][3]