Showing posts tagged mozregression
Just wanted to give some quick updates on the state of mozregression.
Anti-virus false positives
One of the persistent issues with mozregression is that it seems to be persistently detected as a virus by many popular anti-virus scanners. The causes for this are somewhat complex, but at root the problem is that mozregression requires fairly broad permissions to do the things it needs to do (install and run copies of Firefox) and thus its behavior is hard to distinguish from a piece of software doing something malicious.
Recently there have been a number of mitigations which seem to be improving this situation:
- :bryce has been submitting copies of mozregression to Microsoft so that Windows Defender (probably the most popular anti-virus software on this platform) doesn’t flag it.
- I recently released mozregression 4.0.17, which upgrades the GUI dependency for pyinstaller to a later version which sets PE checksums correctly on the generated executable (pyinstaller/pyinstaller#5579).
It’s tempting to lament the fact that this is happening, but in a way I can understand it’s hard to reliably detect what kind of software is legitimate and what isn’t. I take the responsibility for distributing this kind of software seriously, and have pretty strict limits on who has access to the mozregression GitHub repository and what pull requests I’ll merge.
CI ported to GitHub Actions
Due to changes in Travis’s policies, we needed to migrate continuous integration for mozregression to GitHub actions. You can see the gory details in bug 1686039. One possibly interesting wrinkle to others: due to Mozilla’s security policy, we can’t use (most) external actions inside our GitHub repository. I thus rewrote the logic for uploading a mozregression release to GitHub for MacOS and Linux GUI builds (Windows builds are still happening via AppVeyor for now) from scratch. Feel free to check the above out if you have a similar need.
MacOS Big Sur
As of version 4.0.17, the mozregression GUI now works on MacOS Big Sur. It is safe to ask community members to install and use it on this platform (though note the caveats due to the bundle being unsigned).
Usage Dashboard
Fulfilling a promise I implied last year, I created a public dataset for mozregression and created an dashboard tracking mozregression use using Observable. There are a few interesting insights and trends there that can be gleaned from our telemetry. I’d be curious if the community can find any more!
Periodically the discussion comes up about pruning away old stored Firefox build artifacts in S3. Each build is tens of megabytes, multiply that by the number of platforms we support and the set of revisions we churn through on a daily basis, and pretty soon you’re talking about real money.
This came up recently in a discussion about removing the legacy taskcluster deployment — what do we actually lose by cutting back our archive of integration builds? The main reason to keep them around is to facilitate bisection testing with mozregression, to find out when a bug was introduced. Up to now, discussions about this have been a bit hand-wavey: we do keep logs about who’s accessing old builds, but it’s never been clear whether it was mozregression accessing them or something else.
Happily, now that mozregression has some telemetry, it’s a little easier to get some answers on what people are actually doing. This query gets the distribution of build ages (launched or bisected) over the past 6 months, at a month long granularity.1 Ages are relative to the date mozregression was launched: for example, if someone asked for a build from May 2019 in June 2020, the number would be “13”.
SELECT metrics.string.usage_app AS app,
metrics.string.usage_build_type AS build_type,
DATE_DIFF(DATE(submission_timestamp), IF(LENGTH(metrics.datetime.usage_bad_date) > 0, PARSE_DATE('%Y-%m-%d', substr(metrics.datetime.usage_bad_date, 1, 10)), PARSE_DATE('%Y-%m-%d', substr(metrics.datetime.usage_launch_date, 1, 10))), MONTH) + 1 AS build_age
FROM `moz-fx-data-shared-prod`.org_mozilla_mozregression.usage
WHERE DATE(submission_timestamp) >= DATE_SUB(CURRENT_DATE(), INTERVAL 6 MONTH)
AND client_info.app_display_version NOT LIKE '%dev%'
AND LENGTH(metrics.string.usage_build_type) > 0
AND (LENGTH(metrics.datetime.usage_bad_date) > 0
OR LENGTH(metrics.datetime.usage_launch_date) > 0)
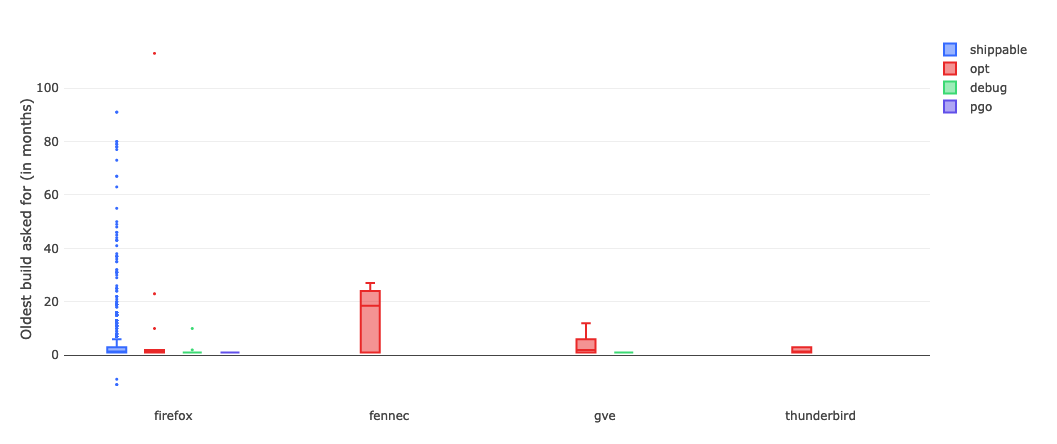
I ran this query on sql.telemetry.mozilla.org and generated a box plot, broken down by product and build type:
link (requires Mozilla LDAP)
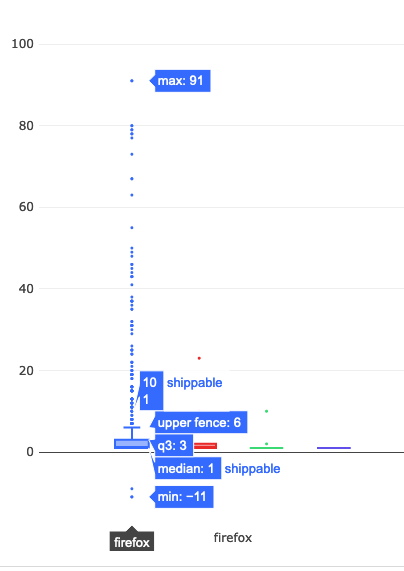
Unsurprisingly, Firefox shippable builds are the number one thing people try to bisect. Let’s take a little bit of a closer look at what’s going on there:
The median value is 1, which indicates that most people are bisecting builds within one month of the day in which mozregression was run. And the upper fence result is 6, suggesting that most of the time people are looking at a regression range that is within a 6 month range. However, looking more closely at the data points themselves (the little points in the chart above), there are a considerable number of outliers where a range greater than 20 months was asked for.
… which brings up to the question that we want to answer. Given that getting old builds isn’t that common (which we sort of knew already, based on the access patterns in the S3 logs), what is the impact of the times that we do? And it’s here where I have to throw up my hands and say “I don’t know” and suggest that we go back to empirical observation and user research.
You can go back to the thread I linked above, and see that core Firefox/Gecko developers find the ability to get a precise regression range for older revisions valuable. One thing that’s worth mentioning is that mozregression isn’t run that often, compared to a product that we ship: on the order of 50 to 100 times per a day. But when it comes to internal tooling, a small amount of use might have a big impact: if a mozregression invocation a developer a few hours (or more), that’s a real benefit to Firefox and Mozilla. The same argument might apply here, where a small number of bisections on older builds might have a disproportionate impact on the quality of the product.
Thanks to @AnAverageHuman, mozregression once again has an easy to use and install GUI version for Linux! This used to work a few years ago, but got broken with some changes in the mozregression-python2 era and didn’t get resolved until now:
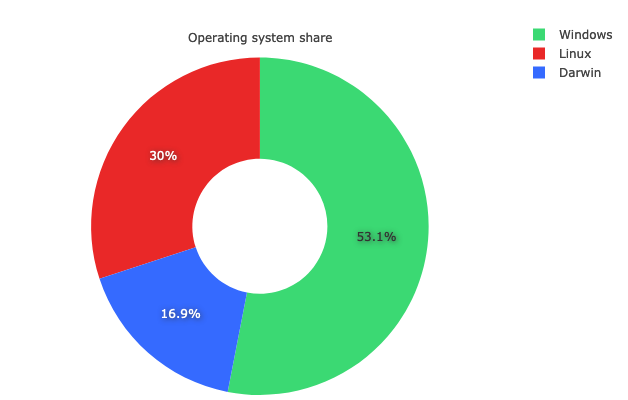
This is an area where using telemetry in mozregression can help us measure the impact of a change like this: although Windows still dominates in terms of marketshare, Linux is very widely used by contributors — of the usage of mozregression in the past 2 months, fully 30% of the sessions were on Linux (and it is possible we were undercounting that due to bug 1646402):
link to query (internal-only)
It will be interesting to watch the usage numbers for Linux evolve over the next few months. In particular, I’m curious to see what percentage of users on that platform prefer a GUI.
Appendix: reducing mozregression-GUI’s massive size
One thing that’s bothered me a bunch lately is that the mozregression GUI’s size is massive and this is even more apparent on Linux, where the initial distribution of the GUI came in at over 120 megabytes! Why so big? There were a few reasons:
- PySide2 (the GUI library we use) is very large (10s of megabytes), and PyInstaller packages all of it by default into your application distribution.
- The binary/rust portions of the Glean Python SDK were been built with debugging information included (basically as a carry-over when it was a pre-alpha product), which made it 38 megabytes big (!) on Linux.
- On Linux at least, a large number of other system libraries are packaged into the distribution.
A few aspects of this were under our control: Ian Moody (:Kwan) and myself crafted a script to manually remove unneeded PySide2 libraries as part of the packaging process. The Glean team was awesome-as-always and quickly rebuilt Glean without debugging information (this was basically an oversight). Finally, I managed to shave off a few more megabytes by reverting the Linux build to an earlier version of Ubuntu (Xenial), which is something I had been meaning to do anyway.
Even after doing all of these things, the end result is still a little underwhelming: the mozregression GUI distribution on Linux is still 79.5 megabytes big. There are probably other things we could do, but we’re definitely entering the land of diminishing returns.
Honestly, my main takeaway is just not to build an application like this in Python unless you absolutely have to (e.g. you’re building an application which needs system-level access). The web is a pretty wonderful medium for creating graphical applications these days, and by using it you sidestep these type of installation issues.
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
This is a special guest post by non-Glean-team member William Lachance!
This is a continuation of an exploration of adding Glean-based telemetry to a python application, in this case mozregression, a tool for automatically finding the source of Firefox regressions (breakage).
When we left off last time, we had written some test scripts and verified that the data was visible in the debug viewer.
Adding Telemetry to mozregression itself
In many ways, this is pretty similar to what I did inside the sample application: the only significant difference is that these are shipped inside a Python application that is meant to be be installable via pip. This means we need to specify the pings.yaml and metrics.yaml (located inside the mozregression subirectory) as package data inside setup.py:
setup(
name="mozregression",
...
package_data={"mozregression": ["*.yaml"]},
...
)
There were also a number of Glean SDK enhancements which we determined were necessary. Most notably, Michael Droettboom added 32-bit Windows wheels to the Glean SDK, which we need to make building the mozregression GUI on Windows possible. In addition, some minor changes needed to be made to Glean’s behaviour for it to work correctly with a command-line tool like mozregression — for example, Glean used to assume that Telemetry would always be disabled via a GUI action so that it would send a deletion ping, but this would obviously not work in an application like mozregression where there is only a configuration file — so for this case, Glean needed to be modified to check if it had been disabled between runs.
Many thanks to Mike (and others on the Glean team) for so patiently listening to my concerns and modifying Glean accordingly.
Getting Data Review
At Mozilla, we don’t just allow random engineers like myself to start collecting data in a product that we ship (even a semi-internal like mozregression). We have a process, overseen by Data Stewards to make sure the information we gather is actually answering important questions and doesn’t unnecessarily collect personally identifiable information (e.g. email addresses).
You can see the specifics of how this worked out in the case of mozregression in bug 1581647.
Documentation
Glean has some fantastic utilities for generating markdown-based documentation on what information is being collected, which I have made available on GitHub:
https://github.com/mozilla/mozregression/blob/master/docs/glean/metrics.md
The generation of this documentation is hooked up to mozregression’s continuous integration, so we can sure it’s up to date.
I also added a quick note to mozregression’s web site describing the feature, along with (very importantly) instructions on how to turn it off.
Enabling Data Ingestion
Once a Glean-based project has passed data review, getting our infrastructure to ingest it is pretty straightforward. Normally we would suggest just filing a bug and let us (the data team) handle the details, but since I’m on that team, I’m going to go a (little bit) of detail into how the sausage is made.
Behind the scenes, we have a collection of ETL (extract-transform-load) scripts in the probe-scraper repository which are responsible for parsing the ping and probe metadata files that I added to mozregression in the step above and then automatically creating BigQuery tables and updating our ingestion machinery to insert data passed to us there.
There’s quite a bit of complicated machinery being the scenes to make this all work, but since it’s already in place, adding a new thing like this is relatively simple. The changeset I submitted as part of a pull request to probe-scraper was all of 9 lines long:
diff --git a/repositories.yaml b/repositories.yaml
index dffcccf..6212e55 100644
--- a/repositories.yaml
+++ b/repositories.yaml
@@ -239,3 +239,12 @@ firefox-android-release:
- org.mozilla.components:browser-engine-gecko-beta
- org.mozilla.appservices:logins
- org.mozilla.components:support-migration
+mozregression:
+ app_id: org-mozilla-mozregression
+ notification_emails:
+ - wlachance@mozilla.com
+ url: 'https://github.com/mozilla/mozregression'
+ metrics_files:
+ - 'mozregression/metrics.yaml'
+ ping_files:
+ - 'mozregression/pings.yaml'
A Pretty Graph
With the probe scraper change merged and deployed, we can now start querying! A number of tables are automatically created according to the schema outlined above: notably “live” and “stable” tables corresponding to the usage ping. Using sql.telemetry.mozilla.org we can start exploring what’s out there. Here’s a quick query I wrote up:
SELECT DATE(submission_timestamp) AS date,
metrics.string.usage_variant AS variant,
count(*),
FROM `moz-fx-data-shared-prod`.org_mozilla_mozregression_stable.usage_v1
WHERE DATE(submission_timestamp) >= '2020-04-14'
AND client_info.app_display_version NOT LIKE '%.dev%'
GROUP BY date, variant;
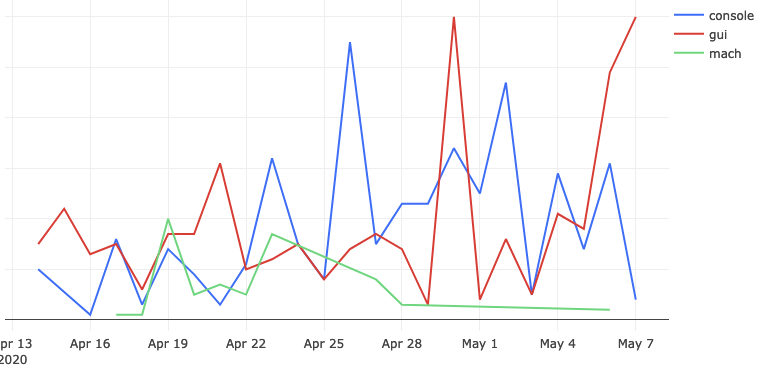
… which generates a chart like this:
This chart represents the absolute volume of mozregression usage since April 14th 2020 (around the time when we first released a version of mozregression with Glean telemetry), grouped by mozregression “variant” (GUI, console, and mach) and date - you can see that (unsurprisingly?) the GUI has the highest usage. I’ll talk about this more in an upcoming installment, speaking of…
Next Steps
We’re not done yet! Next time, we’ll look into making a public-facing dashboard demonstrating these results and making an aggregated version of the mozregression telemetry data publicly accessible to researchers and the general public. If we’re lucky, there might even be a bit of data science. Stay tuned!
Just a quick note that, as a side-effect of the work I mentioned a while ago to add telemetry to mozregression, mozregression now has a graphical Mac client! It’s a bit of a pain to install (since it’s unsigned), but likely worlds easier for the average person to get going than the command-line version. Please feel free to point people to it if you’re looking to get a regression range for a MacOS-specific problem with Firefox.
More details: The Glean Python SDK, which mozregression now uses for telemetry, requires Python 3. This provided the impetus to port the GUI itself to Python 3 and PySide2 (the modern incarnation of PyQt), which brought with it a much easier installation/development experience for the GUI on platforms like Mac and Linux.
I haven’t gotten around to producing GUI binaries for the Linux yet, but it should not be much work.
Speaking of Glean, mozregression, and Telemetry, stay tuned for more updates on that soon. It’s been an adventure!
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
This is a special guest post by non-Glean-team member William Lachance!
As I mentioned last time I talked about mozregression, I have been thinking about adding some telemetry to the system to better understand the usage of this tool, to justify some part of Mozilla spending some cycles maintaining and improving it (assuming my intuition that this tool is heavily used is confirmed).
Coincidentally, the Telemetry client team has been working on a new library for measuring these types of things in a principled way called Glean, which even has python bindings! Using this has the potential in saving a lot of work: not only does Glean provide a framework for submitting data, our backend systems are automatically set up to process data submitted via into Glean into BigQuery tables, which can then easily be queried using tools like sql.telemetry.mozilla.org.
I thought it might be useful to go through some of what I’ve been exploring, in case others at Mozilla are interested in instrumenting their pet internal tools or projects. If this effort is successful, I’ll distill these notes into a tutorial in the Glean documentation.
Initial steps: defining pings and metrics
The initial step in setting up a Glean project of any type is to define explicitly the types of pings and metrics. You can look at a “ping” as being a small bucket of data submitted by a piece of software in the field. A “metric” is something we’re measuring and including in a ping.
Most of the Glean documentation focuses on browser-based use-cases where we might want to sample lots of different things on an ongoing basis, but for mozregression our needs are considerably simpler: we just want to know when someone has used it along with a small number of non-personally identifiable characteristics of their usage, e.g. the mozregression version number and the name of the application they are bisecting.
Glean has the concept of event pings, but it seems like those are there more for a fine-grained view of what’s going on during an application’s use. So let’s define a new ping just for ourselves, giving it the unimaginative name “usage”. This goes in a file called pings.yaml:
---
$schema: moz://mozilla.org/schemas/glean/pings/1-0-0
usage:
description: >
A ping to record usage of mozregression
include_client_id: true
notification_emails:
- wlachance@mozilla.com
bugs:
- http://bugzilla.mozilla.org/123456789/
data_reviews:
- http://example.com/path/to/data-review
We also need to define a list of things we want to measure. To start with, let’s just test with one piece of sample information: the app we’re bisecting (e.g. “Firefox” or “Gecko View Example”). This goes in a file called metrics.yaml:
---
$schema: moz://mozilla.org/schemas/glean/metrics/1-0-0
usage:
app:
type: string
description: >
The name of the app being bisected
notification_emails:
- wlachance@mozilla.com
bugs:
- https://bugzilla.mozilla.org/show_bug.cgi?id=1581647
data_reviews:
- http://example.com/path/to/data-review
expires: never
send_in_pings:
- usage
The data_reviews sections in both of the above are obviously bogus, we will need to actually get data review before landing and using this code, to make sure that we’re in conformance with Mozilla’s data collection policies.
Testing it out
But in the mean time, we can test our setup with the Glean debug pings viewer by setting a special tag (mozregression-test-tag) on our output. Here’s a small python script which does just that:
from pathlib import Path
from glean import Glean, Configuration
from glean import (load_metrics,
load_pings)
mozregression_path = Path.home() / '.mozilla2' / 'mozregression'
Glean.initialize(
application_id="mozregression",
application_version="0.1.1",
upload_enabled=True,
configuration=Configuration(
ping_tag="mozregression-test-tag"
),
data_dir=mozregression_path / "data"
)
Glean.set_upload_enabled(True)
pings = load_pings("pings.yaml")
metrics = load_metrics("metrics.yaml")
metrics.usage.app.set("reality")
pings.usage.submit()
Running this script on my laptop, I see that a respectable JSON payload was delivered to and processed by our servers:
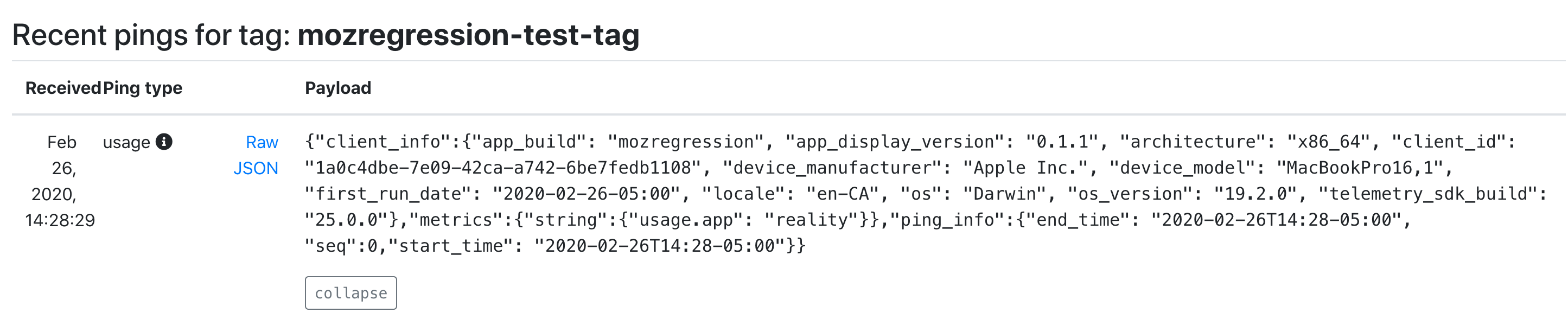
As you can see, we’re successfully processing both the “version” number of mozregression, some characteristics of the machine sending the information (my MacBook in this case), as well as our single measure. We also have a client id, which should tell us roughly how many distinct installations of mozregression are sending pings. This should be more than sufficient for an initial “mozregression usage dashboard”.
Next steps
There are a bunch of things I still need to work through before landing this inside mozregression itself. Notably, the Glean python bindings are python3-only, so we’ll need to port the mozregression GUI to python 3 before we can start measuring usage there. But I’m excited at how quickly this work is coming together: stay tuned for part 2 in a few weeks.
For those who are still wondering, yup, I am still maintaining mozregression, though increasingly reluctantly. Given how important this project is to the development of Firefox (getting a regression window using mozregression is standard operating procedure whenever a new bug is reported in Firefox), it feels like this project is pretty vital, so I continue out of some sense of obligation — but really, someone more interested in Mozilla’a build, automation and testing systems would be better suited to this task: over the past few years, my interests/focus have shifted away from this area to building up Mozilla’s data storage and visualization platform.
This post will describe some of the things that have happened in the last year and where I see the project going. My hope is to attract some new blood to add some needed features to the project and maybe take on some of the maintainership duties.
python 3
The most important update is that, as of today, the command-line version of mozregression (v3.0.1) should work with python 3.5+. modernize did most of the work for us, though there were some unit tests that needed updating: special thanks to @gloomy-ghost for helping with that.
For now, we will continue to support python 2.7 in parallel, mainly because the GUI has not yet been ported to python 3 (more on that later) and we have CI to make sure it doesn’t break.
other updates
The last year has mostly been one of maintenance. Thanks in particular to Ian Moody (:kwan) for his work throughout the year — including patches to adapt mozregression support to our new updates policy and shippable builds (bug 1532412), and Kartikaya Gupta (:kats) for adding support for bisecting the GeckoView example app (bug 1507225).
future work
There are a bunch of things I see us wanting to add or change with mozregression over the next year or so. I might get to some of these if I have some spare cycles, but probably best not to count on it:
- Port the mozregression GUI to Python 3 (bug 1581633) As mentioned above, the command-line client works with python 3, but we have yet to port the GUI. We should do that. This probably also entails porting the GUI to use PyQT5 (which is pip-installable and thus much easier to integrate into a CI process), see bug 1426766.
- Make self-contained GUI builds available for MacOS X (bug 1425105) and Linux (bug 1581643).
- Improve our mechanism for producing a standalone version of the GUI in general. We’ve used cx_Freeze which mostly works ok, but has a number of problems (e.g. it pulls in a bunch of unnecessary dependencies, which bloats the size of the installer). Upgrading the GUI to use python 3 may alleviate some of these issues, but it might be worth considering other options in this space, like Gregory Szorc’s pyoxidizer.
- Add some kind of telemetry to mozregression to measure usage of this tool (bug 1581647). My anecdotal experience is that this tool is pretty invaluable for Firefox development and QA, but this is not immediately apparent to Mozilla’s leadership and it’s thus very difficult to convince people to spend their cycles on maintaining and improving this tool. Field data may help change that story.
- Supporting new Mozilla products which aren’t built (entirely) out of mozilla-central, most especially Fenix (bug 1556042) and Firefox Reality (bug 1568488). This is probably rather involved (mozregression has a big pile of assumptions about how the builds it pulls down are stored and organized) but that doesn’t mean that this work isn’t necessary.
If you’re interested in working on any of the above, please feel free to dive in on one of the above bugs. I can’t offer formal mentorship, but am happy to help out where I can.
Spent a few hours this morning on a few housekeeping issues with mozregression. The web site was badly in need of an update (it was full of references to obsolete stuff like B2G and codefirefox.com) and the usual pile of fixes motivated a new release of the actual software. But most importantly, mozregression now has a proper application icon / logo, thanks to Victoria Wang!

One of the nice parts about working at Mozilla is the flexibility it offers to just hack on stuff that’s important, whether or not it’s part of your formal job description. Maintaining mozregression is pretty far outside my current set of responsibilities (or even interests), but I keep it going because it’s a key tool used by developers team here and no one else seems willing to take it over. Fortunately, tools like appveyor and pypi keep the time suckage to a mostly-reasonable level.
Lots of movement in mozregression (a tool for automatically determining when a regression was introduced in Firefox by bisecting builds on ftp.mozilla.org) in the last few months. Here’s some highlights:
- Support for win64 nightly and inbound builds (Kapil Singh, Vaibhav Agarwal)
- Support for using an http cache to reduce time spent downloading builds (Sam Garrett)
- Way better logging and printing of remaining time to finish bisection (Julien Pagès)
- Much improved performance when bisecting inbound (Julien)
- Support for automatic determination on whether a build is good/bad via a custom script (Julien)
- Tons of bug fixes and other robustness improvements (me, Sam, Julien, others)
Also thanks to Julien, we have a spiffy new website which documents many of these features. If it’s been a while, be sure to update your copy of mozregression to the latest version and check out the site for documentation on how to use the new features described above!
Thanks to everyone involved (especially Julien) for all the hard work. Hopefully the payoff will be a tool that’s just that much more useful to Firefox contributors everywhere.
I just released mozregression 0.24. This would be a good time to note some of the user-visible fixes / additions that have gone in recently:
-
Thanks to Sam Garrett, you can now specify a different branch other than inbound to get finer grained regression ranges from. E.g. if you’re pretty sure a regression occurred on fx-team, you can do something like: mozregression --inbound-branch fx-team -g 2014-09-13 -b 2014-09-14
- Fixed a bug where we could get an incorrect regression range (bug 1059856). Unfortunately the root cause of the bug is still open (it’s a bit tricky to match mozilla-central commits to that of other branches) but I think this most recent fix should make things work in 99.9% of cases. Let me know if I’m wrong.
- Thanks to Julien Pagès, we now download the inbound build metadata in parallel, which speeds up inbound bisection quite significantly
If you know a bit of python, contributing to mozregression is a great way to have a high impact on Mozilla. Many platform developers use this project in their day-to-day work, but there’s still lots of room for improvement.