Showing posts tagged Telemetry
Just wanted to give some quick updates on the state of mozregression.
Anti-virus false positives
One of the persistent issues with mozregression is that it seems to be persistently detected as a virus by many popular anti-virus scanners. The causes for this are somewhat complex, but at root the problem is that mozregression requires fairly broad permissions to do the things it needs to do (install and run copies of Firefox) and thus its behavior is hard to distinguish from a piece of software doing something malicious.
Recently there have been a number of mitigations which seem to be improving this situation:
- :bryce has been submitting copies of mozregression to Microsoft so that Windows Defender (probably the most popular anti-virus software on this platform) doesn’t flag it.
- I recently released mozregression 4.0.17, which upgrades the GUI dependency for pyinstaller to a later version which sets PE checksums correctly on the generated executable (pyinstaller/pyinstaller#5579).
It’s tempting to lament the fact that this is happening, but in a way I can understand it’s hard to reliably detect what kind of software is legitimate and what isn’t. I take the responsibility for distributing this kind of software seriously, and have pretty strict limits on who has access to the mozregression GitHub repository and what pull requests I’ll merge.
CI ported to GitHub Actions
Due to changes in Travis’s policies, we needed to migrate continuous integration for mozregression to GitHub actions. You can see the gory details in bug 1686039. One possibly interesting wrinkle to others: due to Mozilla’s security policy, we can’t use (most) external actions inside our GitHub repository. I thus rewrote the logic for uploading a mozregression release to GitHub for MacOS and Linux GUI builds (Windows builds are still happening via AppVeyor for now) from scratch. Feel free to check the above out if you have a similar need.
MacOS Big Sur
As of version 4.0.17, the mozregression GUI now works on MacOS Big Sur. It is safe to ask community members to install and use it on this platform (though note the caveats due to the bundle being unsigned).
Usage Dashboard
Fulfilling a promise I implied last year, I created a public dataset for mozregression and created an dashboard tracking mozregression use using Observable. There are a few interesting insights and trends there that can be gleaned from our telemetry. I’d be curious if the community can find any more!
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
This is a special guest post by non-Glean-team member William Lachance!
In the last year or so, there’s been a significant shift in the way we (Data Engineering) think about application-submitted data @ Mozilla, but although we have a new application-based SDK based on these principles (the Glean SDK), most of our data tools and documentation have not yet been updated to reflect this new state of affairs.
Much of this story is known inside Mozilla Data Engineering, but I thought it might be worth jotting them down into a blog post as a point of reference for people outside the immediate team. Knowing this may provide some context for some our activities and efforts over the next year or two, at least until our tools, documentation, and tribal knowledge evolve.
In sum, the key differences are:
- Instead of just one application we care about, there are many.
- Instead of just caring about (mostly1) one type of ping (the Firefox main ping), an individual application may submit many different types of pings in the course of their use.
- Instead of having both probes (histogram, scalar, or other data type) and bespoke parametric values in a JSON schema like the telemetry environment, there are now only metric types which are explicitly defined as part of each ping.
The new world is pretty exciting and freeing, but there is some new domain complexity that we need to figure out how to navigate. I’ll discuss that in my last section.
The Old World: Firefox is king
Up until roughly mid–2019, Firefox was the centre of Mozilla’s data world (with the occasional nod to Firefox for Android, which uses the same source repository). The Data Platform (often called “Telemetry”) was explicitly designed to cater to the needs of Firefox Developers (and to a lesser extent, product/program managers) and a set of bespoke tooling was built on top of our data pipeline architecture - this blog post from 2017 describes much of it.
In outline, the model is simple: on the client side, assuming a given user had not turned off Telemetry, during the course of a day’s operation Firefox would keep track of various measures, called “probes”. At the end of that duration, it would submit a JSON-encoded “main ping” to our servers with the probe information and a bunch of other mostly hand-specified junk, which would then find its way to a “data lake” (read: an Amazon S3 bucket). On top of this, we provided a python API (built on top of PySpark) which enabled people inside Mozilla to query all submitted pings across our usage population.
The only type of low-level object that was hard to keep track of was the list of probes: Firefox is a complex piece of software and there are many aspects of it we wanted to instrument to validate performance and quality of the product - especially on the more-experimental Nightly and Beta channels. To solve this problem, a probe dictionary was created to help developers find measures that corresponded to the product area that they were interested in.
On a higher-level, accessing this type of data using the python API quickly became slow and frustrating: the aggregation of years of Firefox ping data was hundreds of terabytes big, and even taking advantage of PySpark’s impressive capabilities, querying the data across any reasonably large timescale was slow and expensive. Here, the solution was to create derived datasets which enabled fast(er) access to pings and other derived measures, document them on docs.telemetry.mozilla.org, and then allow access to them through tools like sql.telemetry.mozilla.org or the Measurement Dashboard.
The New World: More of everything
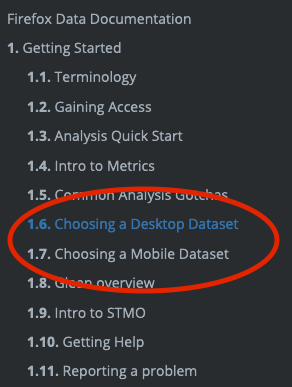
Even in the old world, other products that submitted telemetry existed (e.g. Firefox for Android, Firefox for iOS, the venerable FirefoxOS) but I would not call them first-class citizens. Most of our documentation treated them as (at best) weird edge cases. At the time of this writing, you can see this distinction clearly on docs.telemetry.mozilla.org where there is one (fairly detailed) tutorial called “Choosing a Desktop Dataset” while essentially all other products are lumped into “Choosing a Mobile Dataset”.
While the new universe of mobile products are probably the most notable addition to our list of things we want to keep track of, they’re only one piece of the puzzle. Really we’re interested in measuring all the things (in accordance with our lean data practices, of course) including tools we use to build our products like mozphab and mozregression.
In expanding our scope, we’ve found that mobile (and other products) have different requirements that influence what data we would want to send and when. For example, sending one blob of JSON multiple times per day might make sense for performance metrics on a desktop product (which is usually on a fast, unmetered network) but is much less acceptable on mobile (where every byte counts). For this reason, it makes sense to have different ping types for the same product, not just one. For example, Fenix (the new Firefox for Android) sends a tiny baseline ping2 on every run to (roughly) measure daily active users and a larger metrics ping sent on a (roughly) daily interval to measure (for example) a distribution of page load times.
Finally, we found that naively collecting certain types of data as raw histograms or inside the schema didn’t always work well. For example, encoding session lengths as plain integers would often produce weird results in the case of clock skew. For this reason, we decided to standardize on a set of well-defined metrics using Glean, which tries to minimize footguns. We explicitly no longer allow clients to submit arbitrary JSON or values as part of a telemetry ping: if you have a use case not covered by the existing metrics, make a case for it and add it to the list!
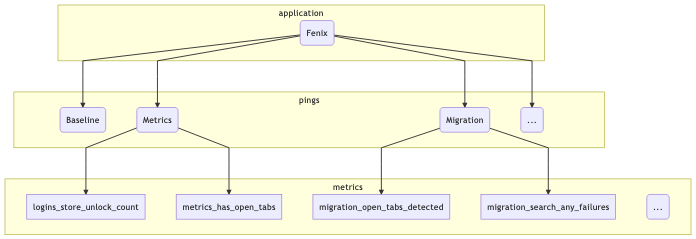
To illustrate this, let’s take a (subset) of what we might be looking at in terms of what the Fenix application sends:
mermaid source
At the top level we segment based on the “application” (just Fenix in this example). Just below that, there are the pings that this application might submit (I listed three: the baseline and metrics pings described above, along with a “migration” ping, which tracks metrics when a user migrates from Fennec to Fenix). And below that there are different types of metrics included in the pings: I listed a few that came out of a quick scan of the Fenix BigQuery tables using my prototype schema dictionary.
This is actually only the surface-level: at the time of this writing, Fenix has no fewer than 12 different ping types and many different metrics inside each of them.3 On a client level, the new Glean SDK provides easy-to-use primitives to help developers collect this type of information in a principled, privacy-preserving way: for example, data review is built into every metric type. But what about after it hits our ingestion endpoints?
Hand-crafting schemas, data ingestion pipelines, and individualized ETL scripts for such a large matrix of applications, ping types, and measurements would quickly become intractable. Instead, we (Mozilla Data Engineering) refactored our data pipeline to parse out the information from the Glean schemas and then create tables in our BigQuery datastore corresponding to what’s in them - this has proceeded as an extension to our (now somewhat misnamed) probe-scraper tool.
You can then query this data directly (see accessing glean data) or build up a derived dataset using our SQL-based ETL system, BigQuery-ETL. This part of the equation has been working fairly well, I’d say: we now have a diverse set of products producing Glean telemetry and submitting it to our servers, and the amount of manual effort required to add each application was minimal (aside from adding new capabilities to the platform as we went along).
What hasn’t quite kept pace is our tooling to make navigating and using this new collection of data tractable.
What could bring this all together?
As mentioned before, this new world is quite powerful and gives Mozilla a bunch of new capabilities but it isn’t yet well documented and we lack the tools to easily connect the dots from “I have a product question” to “I know how to write an SQL query / Spark Job to answer it” or (better yet) “this product dashboard will answer it”.
Up until now, our defacto answer has been some combination of “Use the probe dictionary / telemetry.mozilla.org” and/or “refer to docs.telemetry.mozilla.org”. I submit that we’re at the point where these approaches break down: as mentioned above, there are many more types of data we now need to care about than just “probes” (or “metrics”, in Glean-parlance). When we just cared about the main ping, we could write dataset documentation for its recommended access point (main_summary) and the raw number of derived datasets was managable. But in this new world, where we have N applications times M ping types, the number of canonical ping tables are now so many that documenting them all on docs.telemetry.mozilla.org no longer makes sense.
A few months ago, I thought that Google’s Data Catalog (billed as offering “a unified view of all your datasets”) might provide a solution, but on further examination it only solves part of the problem: it provides only a view on your BigQuery tables and it isn’t designed to provide detailed information on the domain objects we care about (products, pings, measures, and tools). You can map some of the properties from these objects onto the tables (e.g. adding a probe’s description field to the column representing it in the BigQuery table), but Data Calalog’s interface to surfacing and filtering through this information is rather slow and clumsy and requires detailed knowledge of how these higher level concepts relate to BigQuery primitives.
Instead, what I think we need is a new system which allows a data practitioner (Data Scientist, Firefox Engineer, Data Engineer, Product Manager, whoever) to visualize the relevant set of domain objects relevant to their product/feature of interest quickly then map them to specific BigQuery tables and other resources (e.g. visualizations using tools like GLAM) which allow people to quickly answer questions so we can make better products. Basically, I am thinking of some combination of:
- The existing probe dictionary (derived from existing product metadata)
- A new “application” dictionary (derived from some simple to-be-defined application metadata description)
- A new “ping” dictionary (derived from existing product metadata)
- A BigQuery schema dictionary (I wrote up a prototype of this a couple weeks ago) to map between these higher-level objects and what’s in our low-level data store
- Documentation for derived datasets generated by BigQuery-ETL (ideally stored alongside the ETL code itself, so it’s easy to keep up to date)
- A data tool dictionary describing how to easily access the above data in various ways (e.g. SQL query, dashboard plot, etc.)
This might sound ambitious, but it’s basically just a system for collecting and visualizing various types of documentation— something we have proven we know how to do. And I think a product like this could be incredibly empowering, not only for the internal audience at Mozilla but also the external audience who wants to support us but has valid concerns about what we’re collecting and why: since this system is based entirely on systems which are already open (inside GitHub or Mercurial repositories), there is no reason we can’t make it available to the public.
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
This is a special guest post by non-Glean-team member William Lachance!
This is a continuation of an exploration of adding Glean-based telemetry to a python application, in this case mozregression, a tool for automatically finding the source of Firefox regressions (breakage).
When we left off last time, we had written some test scripts and verified that the data was visible in the debug viewer.
Adding Telemetry to mozregression itself
In many ways, this is pretty similar to what I did inside the sample application: the only significant difference is that these are shipped inside a Python application that is meant to be be installable via pip. This means we need to specify the pings.yaml and metrics.yaml (located inside the mozregression subirectory) as package data inside setup.py:
setup(
name="mozregression",
...
package_data={"mozregression": ["*.yaml"]},
...
)
There were also a number of Glean SDK enhancements which we determined were necessary. Most notably, Michael Droettboom added 32-bit Windows wheels to the Glean SDK, which we need to make building the mozregression GUI on Windows possible. In addition, some minor changes needed to be made to Glean’s behaviour for it to work correctly with a command-line tool like mozregression — for example, Glean used to assume that Telemetry would always be disabled via a GUI action so that it would send a deletion ping, but this would obviously not work in an application like mozregression where there is only a configuration file — so for this case, Glean needed to be modified to check if it had been disabled between runs.
Many thanks to Mike (and others on the Glean team) for so patiently listening to my concerns and modifying Glean accordingly.
Getting Data Review
At Mozilla, we don’t just allow random engineers like myself to start collecting data in a product that we ship (even a semi-internal like mozregression). We have a process, overseen by Data Stewards to make sure the information we gather is actually answering important questions and doesn’t unnecessarily collect personally identifiable information (e.g. email addresses).
You can see the specifics of how this worked out in the case of mozregression in bug 1581647.
Documentation
Glean has some fantastic utilities for generating markdown-based documentation on what information is being collected, which I have made available on GitHub:
https://github.com/mozilla/mozregression/blob/master/docs/glean/metrics.md
The generation of this documentation is hooked up to mozregression’s continuous integration, so we can sure it’s up to date.
I also added a quick note to mozregression’s web site describing the feature, along with (very importantly) instructions on how to turn it off.
Enabling Data Ingestion
Once a Glean-based project has passed data review, getting our infrastructure to ingest it is pretty straightforward. Normally we would suggest just filing a bug and let us (the data team) handle the details, but since I’m on that team, I’m going to go a (little bit) of detail into how the sausage is made.
Behind the scenes, we have a collection of ETL (extract-transform-load) scripts in the probe-scraper repository which are responsible for parsing the ping and probe metadata files that I added to mozregression in the step above and then automatically creating BigQuery tables and updating our ingestion machinery to insert data passed to us there.
There’s quite a bit of complicated machinery being the scenes to make this all work, but since it’s already in place, adding a new thing like this is relatively simple. The changeset I submitted as part of a pull request to probe-scraper was all of 9 lines long:
diff --git a/repositories.yaml b/repositories.yaml
index dffcccf..6212e55 100644
--- a/repositories.yaml
+++ b/repositories.yaml
@@ -239,3 +239,12 @@ firefox-android-release:
- org.mozilla.components:browser-engine-gecko-beta
- org.mozilla.appservices:logins
- org.mozilla.components:support-migration
+mozregression:
+ app_id: org-mozilla-mozregression
+ notification_emails:
+ - wlachance@mozilla.com
+ url: 'https://github.com/mozilla/mozregression'
+ metrics_files:
+ - 'mozregression/metrics.yaml'
+ ping_files:
+ - 'mozregression/pings.yaml'
A Pretty Graph
With the probe scraper change merged and deployed, we can now start querying! A number of tables are automatically created according to the schema outlined above: notably “live” and “stable” tables corresponding to the usage ping. Using sql.telemetry.mozilla.org we can start exploring what’s out there. Here’s a quick query I wrote up:
SELECT DATE(submission_timestamp) AS date,
metrics.string.usage_variant AS variant,
count(*),
FROM `moz-fx-data-shared-prod`.org_mozilla_mozregression_stable.usage_v1
WHERE DATE(submission_timestamp) >= '2020-04-14'
AND client_info.app_display_version NOT LIKE '%.dev%'
GROUP BY date, variant;
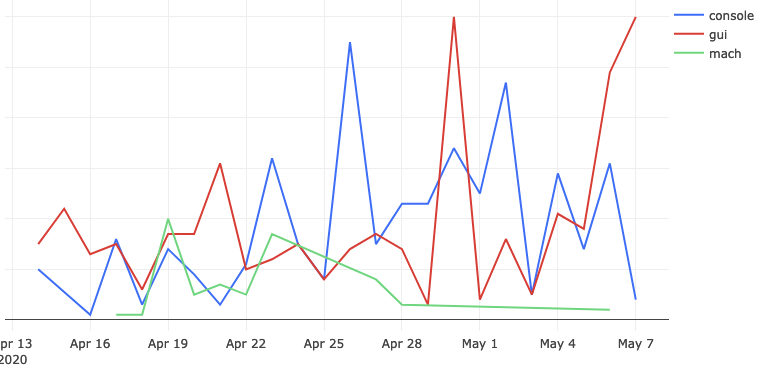
… which generates a chart like this:
This chart represents the absolute volume of mozregression usage since April 14th 2020 (around the time when we first released a version of mozregression with Glean telemetry), grouped by mozregression “variant” (GUI, console, and mach) and date - you can see that (unsurprisingly?) the GUI has the highest usage. I’ll talk about this more in an upcoming installment, speaking of…
Next Steps
We’re not done yet! Next time, we’ll look into making a public-facing dashboard demonstrating these results and making an aggregated version of the mozregression telemetry data publicly accessible to researchers and the general public. If we’re lucky, there might even be a bit of data science. Stay tuned!
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
This is a special guest post by non-Glean-team member William Lachance!
As I mentioned last time I talked about mozregression, I have been thinking about adding some telemetry to the system to better understand the usage of this tool, to justify some part of Mozilla spending some cycles maintaining and improving it (assuming my intuition that this tool is heavily used is confirmed).
Coincidentally, the Telemetry client team has been working on a new library for measuring these types of things in a principled way called Glean, which even has python bindings! Using this has the potential in saving a lot of work: not only does Glean provide a framework for submitting data, our backend systems are automatically set up to process data submitted via into Glean into BigQuery tables, which can then easily be queried using tools like sql.telemetry.mozilla.org.
I thought it might be useful to go through some of what I’ve been exploring, in case others at Mozilla are interested in instrumenting their pet internal tools or projects. If this effort is successful, I’ll distill these notes into a tutorial in the Glean documentation.
Initial steps: defining pings and metrics
The initial step in setting up a Glean project of any type is to define explicitly the types of pings and metrics. You can look at a “ping” as being a small bucket of data submitted by a piece of software in the field. A “metric” is something we’re measuring and including in a ping.
Most of the Glean documentation focuses on browser-based use-cases where we might want to sample lots of different things on an ongoing basis, but for mozregression our needs are considerably simpler: we just want to know when someone has used it along with a small number of non-personally identifiable characteristics of their usage, e.g. the mozregression version number and the name of the application they are bisecting.
Glean has the concept of event pings, but it seems like those are there more for a fine-grained view of what’s going on during an application’s use. So let’s define a new ping just for ourselves, giving it the unimaginative name “usage”. This goes in a file called pings.yaml:
---
$schema: moz://mozilla.org/schemas/glean/pings/1-0-0
usage:
description: >
A ping to record usage of mozregression
include_client_id: true
notification_emails:
- wlachance@mozilla.com
bugs:
- http://bugzilla.mozilla.org/123456789/
data_reviews:
- http://example.com/path/to/data-review
We also need to define a list of things we want to measure. To start with, let’s just test with one piece of sample information: the app we’re bisecting (e.g. “Firefox” or “Gecko View Example”). This goes in a file called metrics.yaml:
---
$schema: moz://mozilla.org/schemas/glean/metrics/1-0-0
usage:
app:
type: string
description: >
The name of the app being bisected
notification_emails:
- wlachance@mozilla.com
bugs:
- https://bugzilla.mozilla.org/show_bug.cgi?id=1581647
data_reviews:
- http://example.com/path/to/data-review
expires: never
send_in_pings:
- usage
The data_reviews sections in both of the above are obviously bogus, we will need to actually get data review before landing and using this code, to make sure that we’re in conformance with Mozilla’s data collection policies.
Testing it out
But in the mean time, we can test our setup with the Glean debug pings viewer by setting a special tag (mozregression-test-tag) on our output. Here’s a small python script which does just that:
from pathlib import Path
from glean import Glean, Configuration
from glean import (load_metrics,
load_pings)
mozregression_path = Path.home() / '.mozilla2' / 'mozregression'
Glean.initialize(
application_id="mozregression",
application_version="0.1.1",
upload_enabled=True,
configuration=Configuration(
ping_tag="mozregression-test-tag"
),
data_dir=mozregression_path / "data"
)
Glean.set_upload_enabled(True)
pings = load_pings("pings.yaml")
metrics = load_metrics("metrics.yaml")
metrics.usage.app.set("reality")
pings.usage.submit()
Running this script on my laptop, I see that a respectable JSON payload was delivered to and processed by our servers:
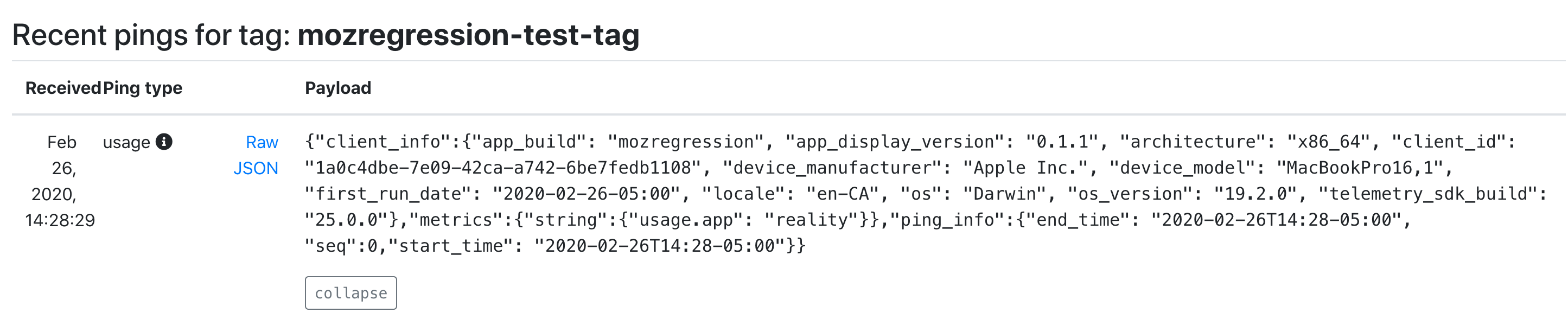
As you can see, we’re successfully processing both the “version” number of mozregression, some characteristics of the machine sending the information (my MacBook in this case), as well as our single measure. We also have a client id, which should tell us roughly how many distinct installations of mozregression are sending pings. This should be more than sufficient for an initial “mozregression usage dashboard”.
Next steps
There are a bunch of things I still need to work through before landing this inside mozregression itself. Notably, the Glean python bindings are python3-only, so we’ll need to port the mozregression GUI to python 3 before we can start measuring usage there. But I’m excited at how quickly this work is coming together: stay tuned for part 2 in a few weeks.
Lately the data engineering team has been looking into productionizing (i.e. running in Airflow) a bunch of models that the data science team has been producing. This often involves languages and environments that are a bit outside of our comfort zone — for example, the next version of Mission Control relies on the R-stan library to produce a model of expected crash behaviour as Firefox is released.
To make things as simple and deterministic as possible, we’ve been building up Docker containers to run/execute this code along with their dependencies, which makes things nice and reproducible. My initial thought was to use just the language-native toolchains to build up my container for the above project, but quickly found a number of problems:
- For local testing, Docker on Mac is slow: when doing a large number of statistical calculations (as above), you can count on your testing iterations taking 3 to 4 (or more) times longer.
- On initial setup, the default R packaging strategy is to have the user of a package like R-stan recompile from source. This can take forever if you have a long list of dependencies with C-compiled extensions (pretty much a given if you’re working in the data space): rebuilding my initial docker environment for missioncontrol-v2 took almost an hour. This isn’t just a problem for local development: it also makes continuous integration using a service like Circle or Travis expensive and painful.
I had been vaguely aware of Conda for a few years, but didn’t really understand its value proposition until I started working on the above project: why bother with a heavyweight package manager when you already have Docker to virtualize things? The answer is that it solves both of the above problems: for local development, you can get something more-or-less identical to what you’re running inside Docker with no performance penalty whatsoever. And for building the docker container itself, Conda’s package repository contains pre-compiled versions of all the dependencies you’d want to use for something like this (even somewhat esoteric libraries like R-stan are available on conda-forge), which brought my build cycle times down to less than 5 minutes.
tl;dr: If you have a bunch of R / python code you want to run in a reproducible manner, consider Conda.
For the last year, we’ve been gradually migrating our backend Telemetry systems from AWS to GCP. I’ve been helping out here and there with this effort, most recently porting a job we used to detect slow tab spinners in Firefox nightly, which produced a small dataset that feeds a small adhoc dashboard which Mike Conley maintains. This was a relatively small task as things go, but it highlighted some features and improvements which I think might be broadly interesting, so I decided to write up a small blog post about it.
Essentially all this dashboard tells you is what percentage of the Firefox nightly population saw a tab spinner over the past 6 months. And of those that did see a tab spinner, what was the severity? Essentially we’re just trying to make sure that there are no major regressions of user experience (and also that efforts to improve things bore fruit):
![]()
Pretty simple stuff, but getting the data necessary to produce this kind of dashboard used to be anything but trivial: while some common business/product questions could be answered by a quick query to clients_daily, getting engineering-specific metrics like this usually involved trawling through gigabytes of raw heka encoded blobs using an Apache Spark cluster and then extracting the relevant information out of the telemetry probe histograms (in this case, FX_TAB_SWITCH_SPINNER_VISIBLE_MS and FX_TAB_SWITCH_SPINNER_VISIBLE_LONG_MS) contained therein.
The code itself was rather complicated (take a look, if you dare) but even worse, running it could get very expensive. We had a 14 node cluster churning through this script daily, and it took on average about an hour and a half to run! I don’t have the exact cost figures on hand (and am not sure if I’d be authorized to share them if I did), but based on a back of the envelope sketch, this one single script was probably costing us somewhere on the order of $10-$40 a day (that works out to between $3650-$14600 a year).
With our move to BigQuery, things get a lot simpler! Thanks to the combined effort of my team and data operations[1], we now produce “stable” ping tables on a daily basis with all the relevant histogram data (stored as JSON blobs), queryable using relatively vanilla SQL. In this case, the data we care about is in telemetry.main (named after the main ping, appropriately enough). With the help of a small JavaScript UDF function, all of this data can easily be extracted into a table inside a single SQL query scheduled by sql.telemetry.mozilla.org.
CREATE TEMP FUNCTION
udf_js_json_extract_highest_long_spinner (input STRING)
RETURNS INT64
LANGUAGE js AS """
if (input == null) {
return 0;
}
var result = JSON.parse(input);
var valuesMap = result.values;
var highest = 0;
for (var key in valuesMap) {
var range = parseInt(key);
if (valuesMap[key]) {
highest = range > 0 ? range : 1;
}
}
return highest;
""";
SELECT build_id,
sum (case when highest >= 64000 then 1 else 0 end) as v_64000ms_or_higher,
sum (case when highest >= 27856 and highest < 64000 then 1 else 0 end) as v_27856ms_to_63999ms,
sum (case when highest >= 12124 and highest < 27856 then 1 else 0 end) as v_12124ms_to_27855ms,
sum (case when highest >= 5277 and highest < 12124 then 1 else 0 end) as v_5277ms_to_12123ms,
sum (case when highest >= 2297 and highest < 5277 then 1 else 0 end) as v_2297ms_to_5276ms,
sum (case when highest >= 1000 and highest < 2297 then 1 else 0 end) as v_1000ms_to_2296ms,
sum (case when highest > 0 and highest < 50 then 1 else 0 end) as v_0ms_to_49ms,
sum (case when highest >= 50 and highest < 100 then 1 else 0 end) as v_50ms_to_99ms,
sum (case when highest >= 100 and highest < 200 then 1 else 0 end) as v_100ms_to_199ms,
sum (case when highest >= 200 and highest < 400 then 1 else 0 end) as v_200ms_to_399ms,
sum (case when highest >= 400 and highest < 800 then 1 else 0 end) as v_400ms_to_799ms,
count(*) as count
from
(select build_id, client_id, max(greatest(highest_long, highest_short)) as highest
from
(SELECT
SUBSTR(application.build_id, 0, 8) as build_id,
client_id,
udf_js_json_extract_highest_long_spinner(payload.histograms.FX_TAB_SWITCH_SPINNER_VISIBLE_LONG_MS) AS highest_long,
udf_js_json_extract_highest_long_spinner(payload.histograms.FX_TAB_SWITCH_SPINNER_VISIBLE_MS) as highest_short
FROM telemetry.main
WHERE
application.channel='nightly'
AND normalized_os='Windows'
AND application.build_id > FORMAT_DATE("%Y%m%d", DATE_SUB(CURRENT_DATE(), INTERVAL 2 QUARTER))
AND DATE(submission_timestamp) >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 QUARTER))
group by build_id, client_id) group by build_id;
In addition to being much simpler, this new job is also way cheaper. The last run of it scanned just over 1 TB of data, meaning it cost us just over $5. Not as cheap as I might like, but considerably less expensive than before: I’ve also scheduled it to only run once every other day, since Mike tells me he doesn’t need this data any more often than that.
[1] I understand that Jeff Klukas, Frank Bertsch, Daniel Thorn, Anthony Miyaguchi, and Wesley Dawson are the principals involved - apologies if I’m forgetting someone.