As part of the Stockwell project, I’ve been hacking on ways to make it easier for developers to diagnose failure of our tests in automation. It’s often very difficult to reproduce an intermittent failure we see in Treeherder locally since the environment is so different, but historically it has been a big hassle to get access to the machines we use in automation for various reasons.
One option that rolled out last year was the so-called one-click loaner, which enabled developers to sign out an virtual machine instance identical to the ones used to run unit tests (at least if the tests are running on Taskcluster, which is increasingly often the case), then execute their particular case with whatever extra debugging options they would find useful. This is a big step forward, but it’s still quite a bit of hassle, since it requires a bunch of manual work on the part of the developer to interact with the instance.
What if we could just re-run the particular test an arbitrary number of times with whatever options we wanted, simply by clicking on a few buttons on Treeherder? I’ve been exploring this for the first few months of 2017 and I’ve come up with a prototype which I think is ready for people to start playing with.
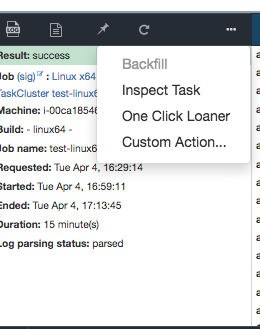
The user interface to this is pretty straightforward. Just find a job you want to retrigger in Treeherder:
Then select the ’…’ option in the panel below and press “Custom Action…”:
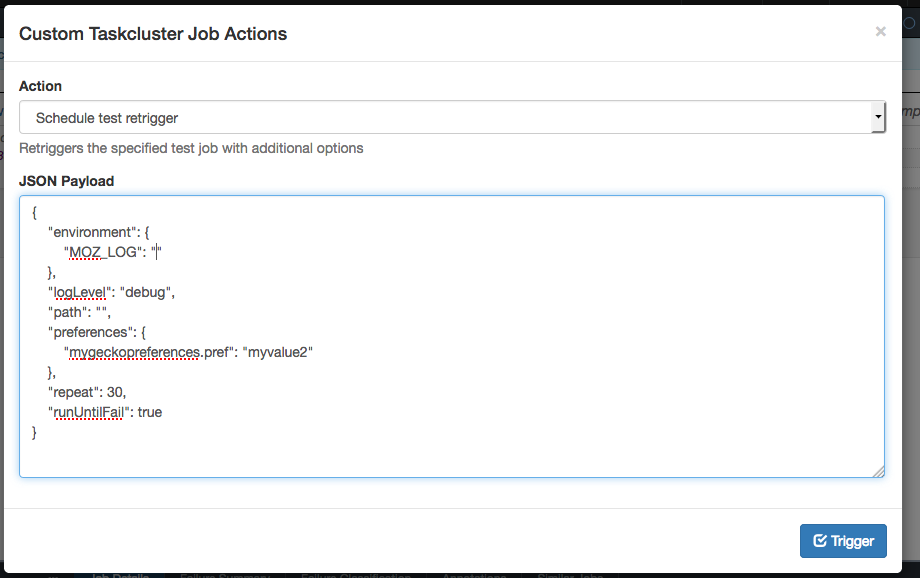
You should get a small piece of JSON to edit, which corresponds to the configuration for the retriggered job:
The main field to edit is “path”. You should set this to the name of the test you want to try retriggering. For example dom/animation/test/css-transitions/test_animation-ready.html. You can also set custom Firefox preferences and environment variables, to turn on different types of debugging.
Unfortunately as usual with a new feature at Mozilla, there are a bunch of limitations and caveats:
This depends on functionality that’s only in Taskcluster, so buildbot jobs are exempt.
No support for Android yet. In combination with the above limitation, this implies that this functionality only works on Linux (at least until other platforms are moved to Taskcluster, which hopefully isn’t that far off).
Browser chrome tests failing in mysterious ways if run repeatedly (bug 1347654)
Only reftest and mochitest are currently supported. XPCShell support is blocked by the lack of support in its harness for running a job repeatedly (bug 1347696). Web Platform Tests need the requisite support in mozharness for just setting up the tests without running them — the same issue that prevents us from debugging such tests with a one-click loaner (bug 1348833).
Aside from fixing the above limitations, the following features would also be really nifty to have:
Ability to trigger a custom job as part of a try push (i.e. not needing to retrigger off an existing job)
Run these jobs under rr, and provide a way to login and interactively debug when the problem is actually reproduced.
I am actually in the process of moving to another team @ Mozilla (more on that in another post), so I probably won’t have a ton of time to work on the above — but I’d be happy to help anyone who’s interested in developing this idea further.
A special shout out to the Taskcluster team for helping me with the development of this feature: in particular the action task implementation from Jonas Finnemann Jensen that made it possible to develop this feature in the first place.
I just added a feature to Treeherder which lets you cancel a set of jobs (say, from a botched try push) much more easily. I’m hopeful that this will be helpful in keeping our resource usage on try more under control.
It uses the “pinboard” feature of Treeherder which very few people are familiar with, so I made a very short video tutorial on how to make use of this feature and put it on the Joy of Automation channel:
Here at Mozilla, we’ve accepted that a certain amount of intermittent failure in our automated testing of Firefox is to be expected. That is, for every push, a subset of the tests that we run will fail for reasons that have nothing to do with the quality (or lack thereof) of the push itself.
On the main integration branches that developers commit code to, we have dedicated staff and volunteers called sheriffs who attempt to distinguish these expected failures from intermittents through a manual classification process using Treeherder. On any given push, you can usually find some failed jobs that have stars beside them, this is the work of the sheriffs, indicating that a job’s failure is “nothing to worry about”:
This generally works pretty well, though unfortunately it doesn’t help developers who need to test their changes on Try, which have the same sorts of failures but no sheriffs to watch them or interpret the results. For this reason (and a few others which I won’t go into detail on here), there’s been much interest in having Treeherder autoclassify known failures.
We have a partially implemented version that attempts to do this based on structured (failure line) information, but we’ve had some difficulty creating a reasonable user interface to train it. Sheriffs are used to being able to quickly tag many jobs with the same bug. Having to go through each job’s failure lines and manually annotate each of them is much more time consuming, at least with the approaches that have been tried so far.
It’s quite possible that this is a solvable problem, but I thought it might be an interesting exercise to see how far we could get training an autoclassifier with only the existing per-job classifications as training data. With some recent work I’ve done on refactoring Treeherder’s database, getting a complete set of per-job failure line information is only a small SQL query away:
Just to give some explanation of this query, the “bug_job_map” provides a list of bugs that have been applied to jobs. The “text_log_step” and “text_log_error” tables contain the actual errors that Treeherder has extracted from the textual logs (to explain the failure). From this raw list of mappings and errors, we can construct a data structure incorporating the job, the assigned bug and the textual errors inside it. For example:
{"bug_number":1202623,"lines":["browser_private_clicktoplay.js Test timed out -","browser_private_clicktoplay.js Found a tab after previous test timed out: http:/<number><number>:<number>/browser/browser/base/content/test/plugins/plugin_test.html -","browser_private_clicktoplay.js Found a browser window after previous test timed out -","browser_private_clicktoplay.js A promise chain failed to handle a rejection: - at chrome://mochikit/content/browser-test.js:<number> - TypeError: this.SimpleTest.isExpectingUncaughtException is not a function","browser_privatebrowsing_newtab_from_popup.js Test timed out -","browser_privatebrowsing_newtab_from_popup.js Found a browser window after previous test timed out -","browser_privatebrowsing_newtab_from_popup.js Found a browser window after previous test timed out -","browser_privatebrowsing_newtab_from_popup.js Found a browser window after previous test timed out -"]}
Some quick google searching revealed that scikit-learn is a popular tool for experimenting with text classifications. They even had a tutorial on classifying newsgroup posts which seemed tantalizingly close to what we needed to do here. In that example, they wanted to predict which newsgroup a post belonged to based on its content. In our case, we want to predict which existing bug a job failure should belong to based on its error lines.
There are obviously some differences in our domain: test failures are much more regular and structured. There are lots of numbers in them which are mostly irrelevant to the classification (e.g. the “expected 12 pixels different, got 10!” type errors in reftests). Ordering of failures might matter. Still, some of the techniques used on corpora of normal text documents for training a classifier probably map nicely onto what we’re trying to do here: it seems plausible that weighting words which occur more frequently less strongly against ones that are less common would be helpful, for example, and that’s one thing their default transformers does.
In any case, I built up a small little script to download a subset of the downloaded data (from November 1st to November 23rd), used it as training data for a classifier, then tested that against another subset of test failures between November 24th and 28th.
With absolutely no tweaking whatsoever, I got an accuracy rate of 75% on the test data. That is, the algorithm chose the correct classification given the failure text 1312 times out of 1959. Not bad for a first attempt!
After getting that working, I did some initial testing to see if I could get better results by reusing some of the error ETL summary code in Treeherder we use for bug suggestions, but the results were pretty much the same.
So what’s next? This seems like a wide open area to me, but some initial areas that seem worth exploring, if we wanted to take this idea further:
Investigate cases where the autoclassification failed or had a near miss. Is there a pattern here? Is there something simple we could do, either by tweaking the input data or using a better vectorizer/tokenizer?
Have a confidence threshold for using the autoclassifier’s data. It seems likely to me that many of the cases above where we got the wrong were cases where the classifier itself wasn’t that confident in the result (vs. others). We can either present that in the user interface or avoid classifications for these cases altogether (and leave it up to a human being to make a decision on whether this is an intermittent).
Using the structured log data inside the database as input to a classifier. Structured log data here is much more regular and denser than the free text that we’re using. Even if it isn’t explicitly classified, we may well get better results by using it as our input data.
If you’d like to experiment with the data and/or code, I’ve put it up on a github repository.
Just wanted to talk about some recent performance improvements we’ve made recently to Treeherder:
Bug 1311511: Changed the repository endpoint so we don’t do 40 redundant database queries (this was generally innocuous, but could delay loading by 400ms if the database was under heavy load).
Bug 1310016: Persisted database connections across requests (this can save ~40–50ms per request, of which there can be 5–10 when loading a Treeherder page).
Bug 1308782: Don’t download job type and group information from the server to get a “sorting order” for the job lists. This was never necessary, but it’s gotten exponentially more painful as people have added job types to Treeherder (job type information is now around a megabyte of JSON these days). This saves 5–10 seconds on a typical page load.
There’s more to come, but with these changes Treeherder should be faster for everyone to load. It should be particularly noticeable on try pushes, where the last item was by far the largest bottleneck. Here’s a youtube video of the changes:
The original is on the left. The newer, faster Treeherder is on the right. Pay particular attention to how much faster the job information populates.
Moral of the story? Optimization can be helpful, but it’s better if you can avoid doing the work altogether.