Yep, still working on this project. We’ve shifted gears somewhat from trying to identify problems in a time series of error aggregates to tracking somewhat longer term trends release over release, to fill the needs of the release management team at Mozilla. It’s been a good change, I think. A bit of a tighter focus.
The main motivator for this work is that the ADI (active daily install) numbers that crash stats used to provide as input to a similar service, AreWeStableYet (link requires Mozilla credentials), are going away and we need some kind of replacement. I’ve been learning about this older system worked (this blog post from KaiRo was helpful) and trying to develop a replacement which reproduces some of its useful characteristics while also taking advantage of some of the new features that are provided by the error_aggregates dataset and the mission control user interface.
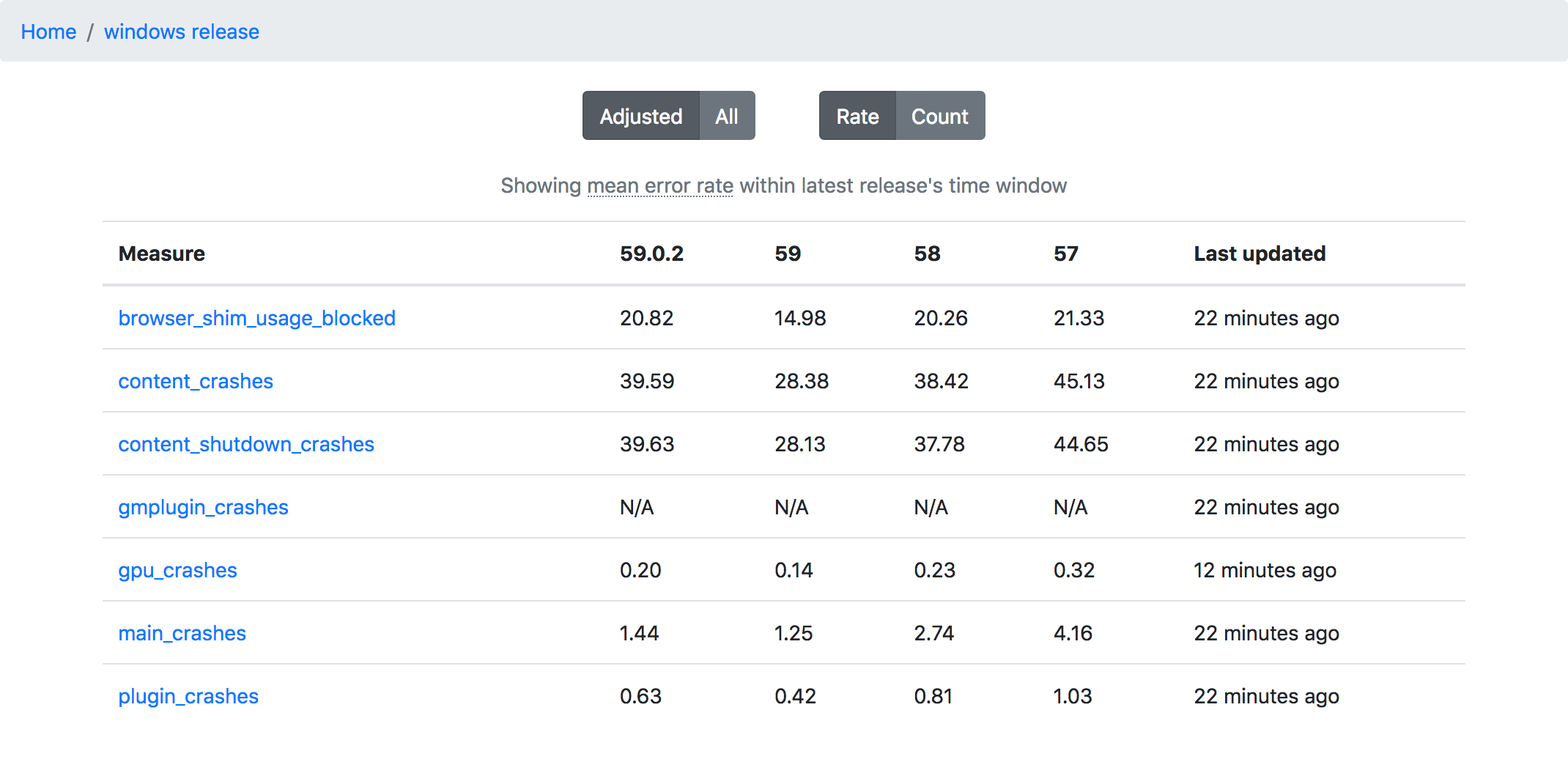
Some preliminary screenshots of what I’ve been able to come up with:
![]()
![]()
One of the key things to keep in mind with this dashboard is that by default it shows an adjusted set of rates (defined as total number of events divided by total usage khours), which means we compare the latest release to the previous one within the same time interval.
So if, say, the latest release is “59” and it’s been out for two weeks, we will compare it against the previous release (“58”) in its first two weeks. As I’ve said here before, things are always crashier when they first go out, and comparing a new release to one that has been out in the field for some time is not a fair comparison at all.
This adjusted view of things is still not apples-to-apples: the causality of crashes and errors is so complex that there will always be differences between releases which are beyond our control or even understanding. Many crash reports, for example, have nothing to do with our product but with third party software and web sites beyond our control. That said, I feel like this adjusted rate is still good enough to tell us (broadly speaking) (1) whether our latest release / beta / nightly is ok (i.e. there is no major showstopper issue) and (2) whether our overall error rate is going up or down over several versions (if there is a continual increase in our crash rate, it might point to a problem in our release/qa process).
Interestingly, the first things that we’ve found with this system are not real problems with the product but data collection issues:
Data issues aside, the indications are that there’s been a steady increase in the quality of Firefox over the last few releases based on the main user facing error metric we’ve cared about in the past (main crashes), so that’s good. :)
If you want to play with the system yourself, the development instance is still up. We will probably look at making this thing “official” next quarter.
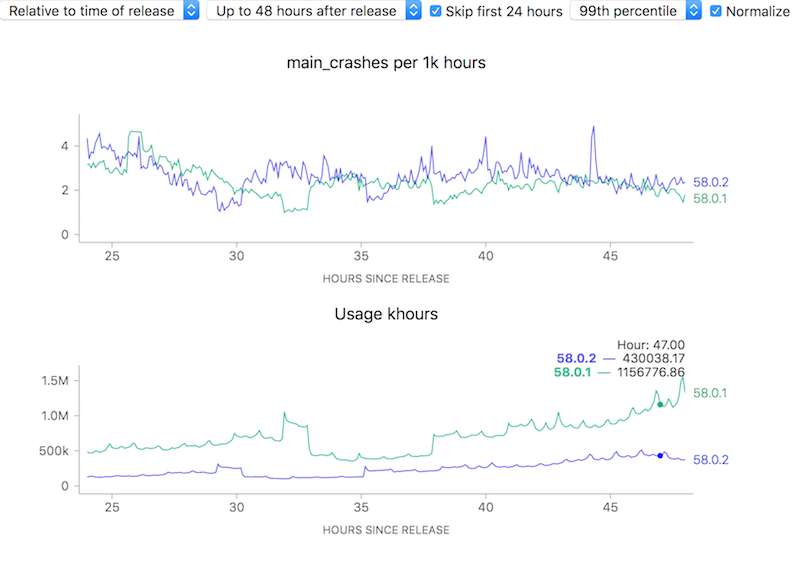
To attempt to make complex phenomena more understandable, we often use derived measures when representing Telemetry data at Mozilla. For error rates for example, we often measure things in terms of “X per khours of use” (where X might be “main crashes”, “appearance of the slow script dialogue”). I.e. instead of showing a raw count of errors we show a rate. Normally this is a good thing: it allows the user to easily compare two things which might have different raw numbers for whatever reason but where you’d normally expect the ratio to be similar. For example, we see that although the uptake of the newly-released Firefox 58.0.2 is a bit slower than 58.0.1, the overall crash rate (as sampled every 5 minutes) is more or less the same after about a day has rolled around:
![]()
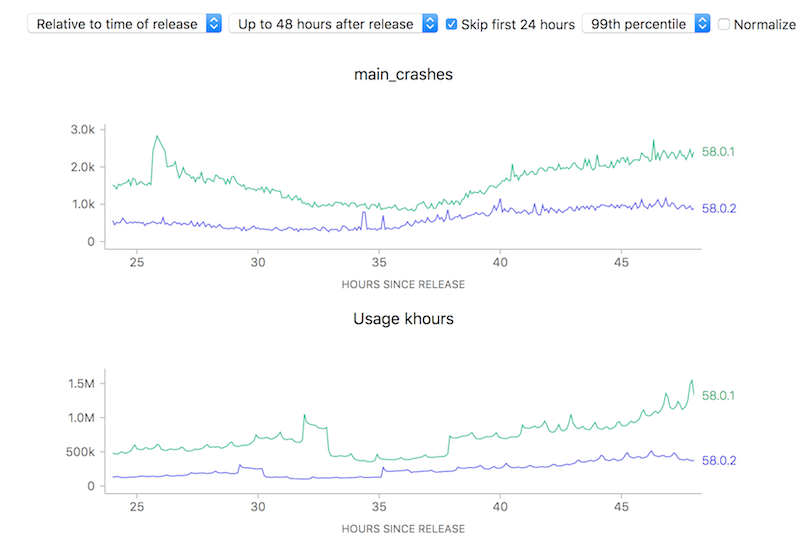
On the other hand, looking at raw counts doesn’t really give you much of a hint on how to interpret the results. Depending on the scale of the graph, the actual rates could actually resolve to being vastly different:
![]()
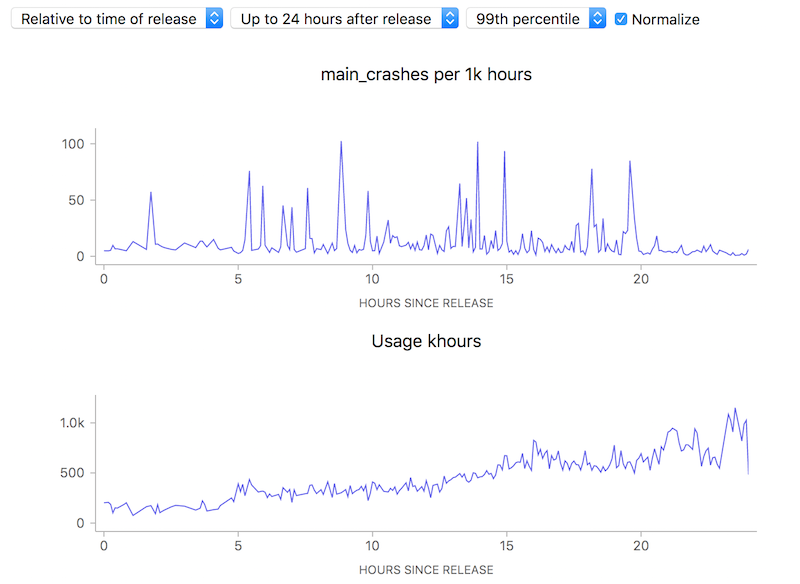
Ok, so this simple tool (using a ratio) is useful. Yay! Unfortunately, there is one case where using this technique can lead to a very deceptive visualization: when the number of samples is really small, a few outliers can give a really false impression of what’s really happening. Take this graph of what the crash rate looked like just after Firefox 58.0 was released:
![]()
10 to 100 errors per 1000 hours, say it isn’t so? But wait, how many errors do we have absolutely? Hovering over a representative point in the graph with the normalization (use of a ratio) turned off:
![]()
We’re really only talking about something between 1 to 40 crashes events over a relatively small number of usage hours. This is clearly so little data that we can’t (and shouldn’t) draw any kind of conclusion whatsoever.
Ok, so that’s just science 101: don’t jump to conclusions based on small, vastly unrepresentative samples. Unfortunately due to human psychology people tend to assume that charts like this are authoritative and represent something real, absent an explanation otherwise — and the use of a ratio obscured the one fact (extreme lack of data) that would have given the user a hint on how to correctly interpret the results. Something to keep in mind as we build our tools.
This is going to sound corny, but helping people really is one of my favorite things at Mozilla, even with projects I have mostly moved on from. As someone who primarily works on internal tools, I love hearing about bugs in the software I maintain or questions on how to use it best.
Given this, you might think that getting in touch with me via irc or slack is the fastest and best way to get your issue addressed. We certainly have a culture of using these instant-messaging applications at Mozilla for everything and anything. Unfortunately, I have found that being “always on” to respond to everything hasn’t been positive for either my productivity or mental health. My personal situation aside, getting pinged on irc while I’m out of the office often results in stuff getting lost — the person who asked me the question is often gone by the time I return and am able to answer.
With that in mind, here’s some notes on my preferred conversation style when making initial contact about an issue:
- Please don’t send context-free pings on irc. It has been explained elsewhere why this doesn’t work that well, so I won’t repeat the argument here.
- If you are at all suspicious that your issue might be a bug in some software maintain, just file a bug and needinfo me. That puts us right on the path to documenting the problem and getting to a resolution — even if something turns out to not be a bug, if you’re seeing an unexpected error it points to a usability issue.
- For everything else, email is best. I do check it quite frequently between bursts of work (i.e. many times a day). I promise I won’t leave you hanging for days on end as long as I’m not on vacation.
These aren’t ironclad rules. If your question pertains to a project I’m actively working on, it might make sense to ping me on irc first (preferably on a channel where other people are around who might also be able to help). If it’s an actual emergency, then of course talk to me on irc straight away (or even call me on my phone) — if I don’t respond, then fall back to filing bug or sending email. Use common sense.
One of my new years resolutions is to also apply these rules to my communications with others at Mozilla as well, so if you see my violating it feel free to point me back at this post. Or just use this handy meme I created:

(this post probably won’t make much sense unless you have been a user of Twitter since/during 2016–2018)
Decided to kill my Twitter account today. Probably most people won’t miss my presence there as I haven’t actively posting on the site in quite some time, but I did check it quite frequently. I suspect it consumed (and I’m ashamed to admit this), at least an hour of my day on average. Twitter when I wake up, Twitter on the streetcar, Twitter every god damn empty moment.
Of all the large social media propertes, I find Twitter by far leads in the amount of negative sentiment it displays, especially in the last year or so. Donald Trump, #GamerGate, Brexit, Nazis, the list goes on. That’s probably why it is so uniquely capable of grabbing my attention in particular, there’s some dark part of me which gravitates towards exactly this type of content.
Now, due to the filter bubble effect, 99% of what I see on that site is a negative response to those things, but so what? The overwhelming of effect of my interaction with the site is simply to make me more more fearful and angry, nothing more. The very format of Twitter (brief bursts of performative text) doesn’t encourage any kind of intelligent or compassionate reaction to what you are seeing or reading. It would be one thing if the negative things I saw on Twitter motivated me to take a positive action of any kind, but if the net effect of hearing bad news is just to make you feel bad, then what’s the point?
I’m not much of a fan of Facebook either, but it has (less often than I would like, but sometimes) been a platform for facilitating worthwhile social and cultural interactions both on the site and off. I could probably count the number of similar exchanges I have had on Twitter on one hand — overwhelmingly my experience with twitter is that engagement (posting) leads only to a regrettable salvo of petty bickering and well actuallys.
So, let’s see what life on the other side of this site is like. The demons which pulled me to Twitter every day are no doubt still there… but hopefully they’ll be easier to handle without the influence of a technology which amplifies their effect.
Further reading:
Just a quick announcement that I’ve taken it upon myself to assume some maintership duties of the popular MetricsGraphics library and have released a new version with some bug fixes (2.12.0). We use this package pretty extensively at Mozilla for visualizing telemetry and other time series data, but its original authors (Hamilton Ulmer and Ali Almossawi) have mostly moved on to other things so there was a bit of a gap in getting fixes and improvements in that I hope to fill.
I don’t yet claim to be an expert in this library (which is quite rich and complex), but I’m sure I’ll learn more as I go along. At least initially, I expect that the changes I make will be small and primarily targetted to filling the needs of the Mission Control project.
Note that this emphatically does not mean I am promising to respond to every issue/question/pull request made against the project. Like my work with mozregression and perfherder, my maintenance work is being done on a best-effort basis to support Mozilla and the larger open source community. I’ll help people out where I can, but there are only so many working hours in a day and I need to spend most of those pushing my team’s immediate projects and deliverables forward! In particular, when it comes to getting pull requests merged, small, self-contained and logical changes with good commit messages will take priority.
Ok, after a series of posts extolling the virtues of my current project, it’s time to take a more critical look at some of its current limitations, and what we might do about them. In my introductory post, I talked about how Mission Control can let us know how “crashy” a new release is, within a short interval of it being released. I also alluded to the fact that things appear considerably worse when something first goes out, though I didn’t go into a lot of detail about how and why that happens.
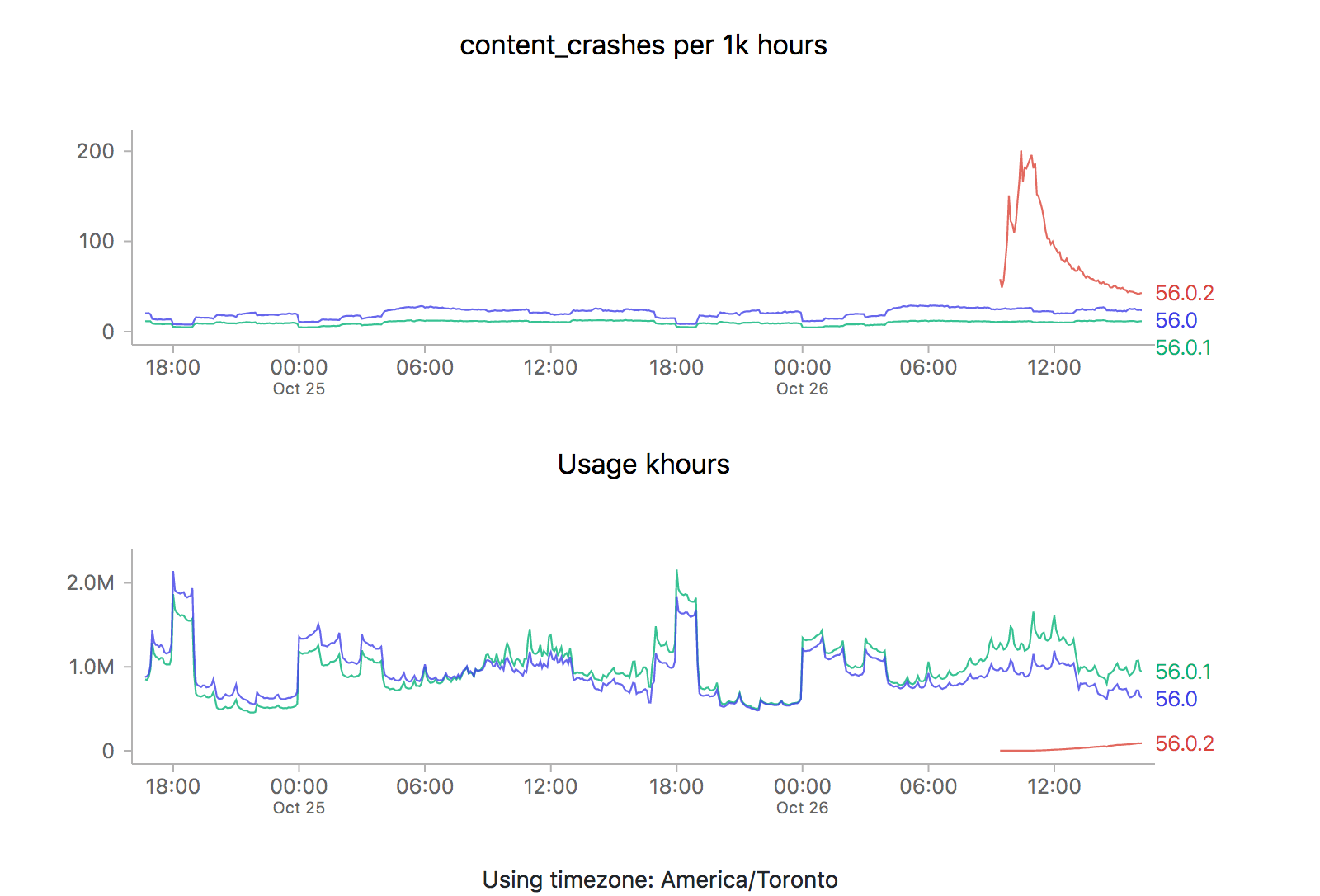
It just so happens that a new point release (56.0.2) just went out, so it’s a perfect opportunity to revisit this issue. Let’s take a look at what the graphs are saying (each of the images is also a link to the dashboard where they were generated):
![]()
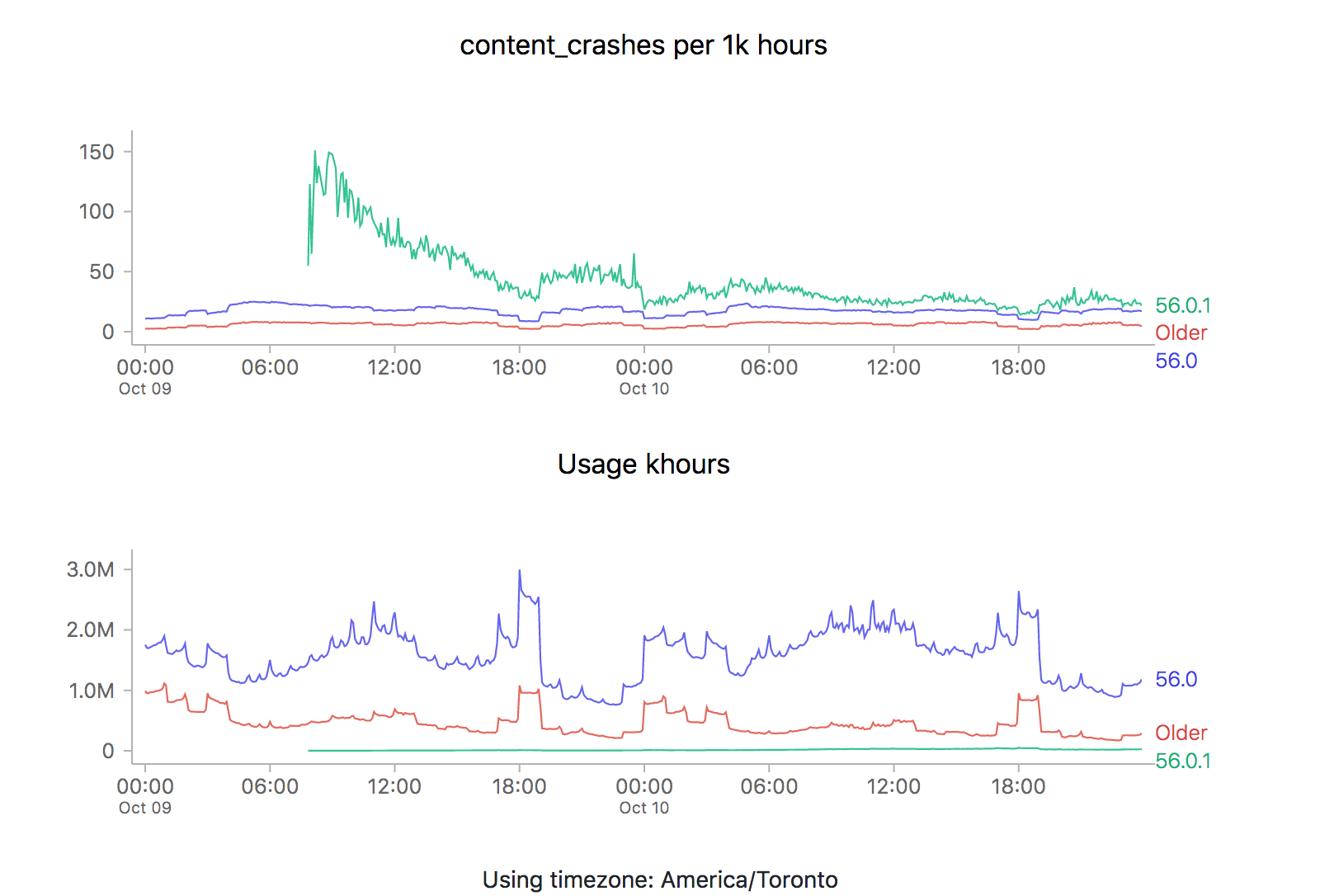
ZOMG! It looks like 56.0.2 is off the charts relative to the two previous releases (56.0 and 56.0.1). Is it time to sound the alarm? Mission control abort? Well, let’s see what happens the last time we rolled something new out, say 56.0.1:
![]()
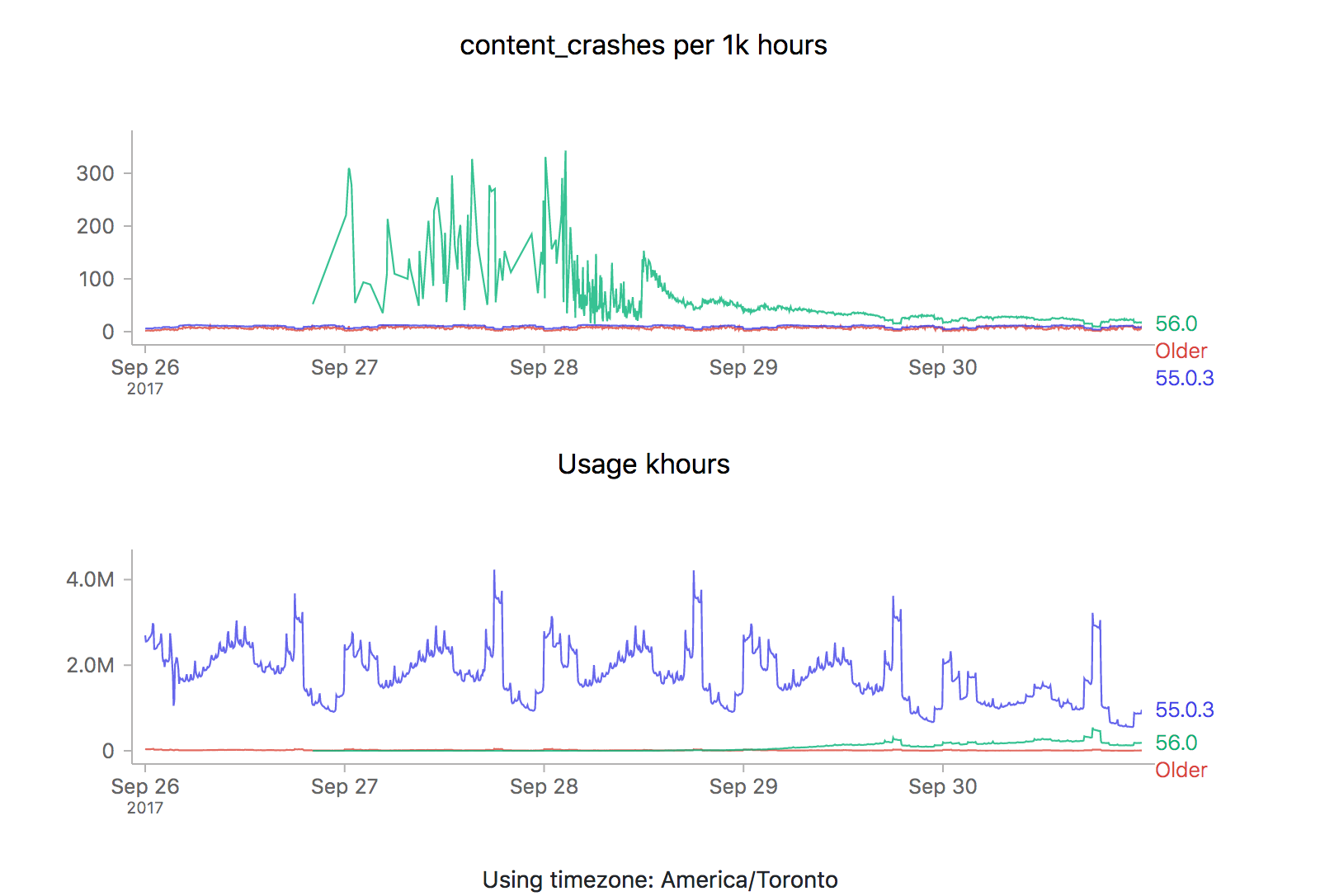
We see the exact same pattern. Hmm. How about 56.0?
![]()
Yep, same pattern here too (actually slightly worse).
What could be going on? Let’s start by reviewing what these time series graphs are based on. Each point on the graph represents the number of crashes reported by telemetry “main” pings corresponding to that channel/version/platform within a five minute interval, divided by the number of usage hours (how long users have had Firefox open) also reported in that interval. A main ping is submitted under a few circumstances:
- The user shuts down Firefox
- It’s been about 24 hours since the last time we sent a main ping.
- The user starts Firefox after Firefox failed to start properly
- The user changes something about Firefox’s environment (adds an addon, flips a user preference)
A high crash rate either means a larger number of crashes over the same number of usage hours, or a lower number of usage hours over the same number of crashes. There are several likely explanations for why we might see this type of crashy behaviour immediately after a new release:
- A Firefox update is applied after the user restarts their browser for any reason, including their browser crash. Thus a user whose browser crashes a lot (for any reason), is more prone to update to the latest version sooner than a user that doesn’t crash as much.
- Inherently, any crash data submitted to telemetry after a new version is released will have a low number of usage hours attached, because the client would not have had a chance to use it much (because it’s so new).
Assuming that we’re reasonably satisfied with the above explanation, there’s a few things we could try to do to correct for this situation when implementing an “alerting” system for mission control (the next item on my todo list for this project):
- Set “error” thresholds for each crash measure sufficiently high that we don’t consider these high initial values an error (i.e. only alert if there is are 500 crashes per 1k hours).
- Only trigger an error threshold when some kind of minimum quantity of usage hours has been observed (this has the disadvantage of potentially obscuring a serious problem until a large percentage of the user population is affected by it).
- Come up with some expected range of what we expect a value to be for when a new version of firefox is first released and ratchet that down as time goes on (according to some kind of model of our previous expectations).
The initial specification for this project called for just using raw thresholds for these measures (discounting usage hours), but I’m becoming increasingly convinced that won’t cut it. I’m not a quality control expert, but 500 crashes for 1k hours of use sounds completely unacceptable if we’re measuring things at all accurately (which I believe we are given a sufficient period of time). At the same time, generating 20–30 “alerts” every time a new release went out wouldn’t particularly helpful either. Once again, we’re going to have to do this the hard way…
—
If this sounds interesting and you have some react/d3/data visualization skills (or would like to gain some), learn about contributing to mission control.
Shout out to chutten for reviewing this post and providing feedback and additions.
One of the great design decisions that was made for Treeherder was a strict seperation of the client and server portions of the codebase. While its backend was moderately complicated to get up and running (especially into a state that looked at all like what we were running in production), you could get its web frontend running (pointed against the production data) just by starting up a simple node.js server. This dramatically lowered the barrier to entry, for Mozilla employees and casual contributors alike.
I knew right from the beginning that I wanted to take the same approach with Mission Control. While the full source of the project is available, unfortunately it isn’t presently possible to bring up the full stack with real data, as that requires privileged access to the athena/parquet error aggregates table. But since the UI is self-contained, it’s quite easy to bring up a development environment that allows you to freely browse the cached data which is stored server-side (essentially: git clone https://github.com/mozilla/missioncontrol.git && yarn install && yarn start).
In my experience, the most interesting problems when it comes to projects like these center around the question of how to present extremely complex data in a way that is intuitive but not misleading. Probably 90% of that work happens in the frontend. In the past, I’ve had pretty good luck finding contributors for my projects (especially Perfherder) by doing call-outs on this blog. So let it be known: If Mission Control sounds like an interesting project and you know React/Redux/D3/MetricsGraphics (or want to learn), let’s work together!
I’ve created some good first bugs to tackle in the github issue tracker. From there, I have a galaxy of other work in mind to improve and enhance the usefulness of this project. Please get in touch with me (wlach) on irc.mozilla.org #missioncontrol if you want to discuss further.
Time for an overdue post on the mission control project that I’ve been working on for the past few quarters, since I transitioned to the data platform team.
One of the gaps in our data story when it comes to Firefox is being able to see how a new release is doing in the immediate hours after release. Tools like crashstats and the telemetry evolution dashboard are great, but it can take many hours (if not days) before you can reliably see that there is an issue in a metric that we care about (number of crashes, say). This is just too long — such delays unnecessarily retard rolling out a release when it is safe (because there is a paranoia that there might be some lingering problem which we we’re waiting to see reported). And if, somehow, despite our abundant caution a problem did slip through it would take us some time to recognize it and roll out a fix.
Enter mission control. By hooking up a high-performance spark streaming job directly to our ingestion pipeline, we can now be able to detect within moments whether firefox is performing unacceptably within the field according to a particular measure.
To make the volume of data manageable, we create a grouped data set with the raw count of the various measures (e.g. main crashes, content crashes, slow script dialog counts) along with each unique combination of dimensions (e.g. platform, channel, release).
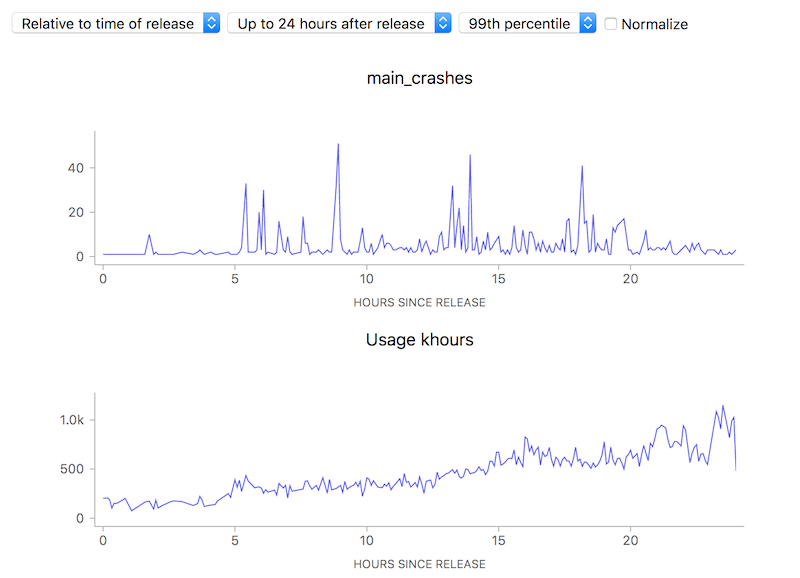
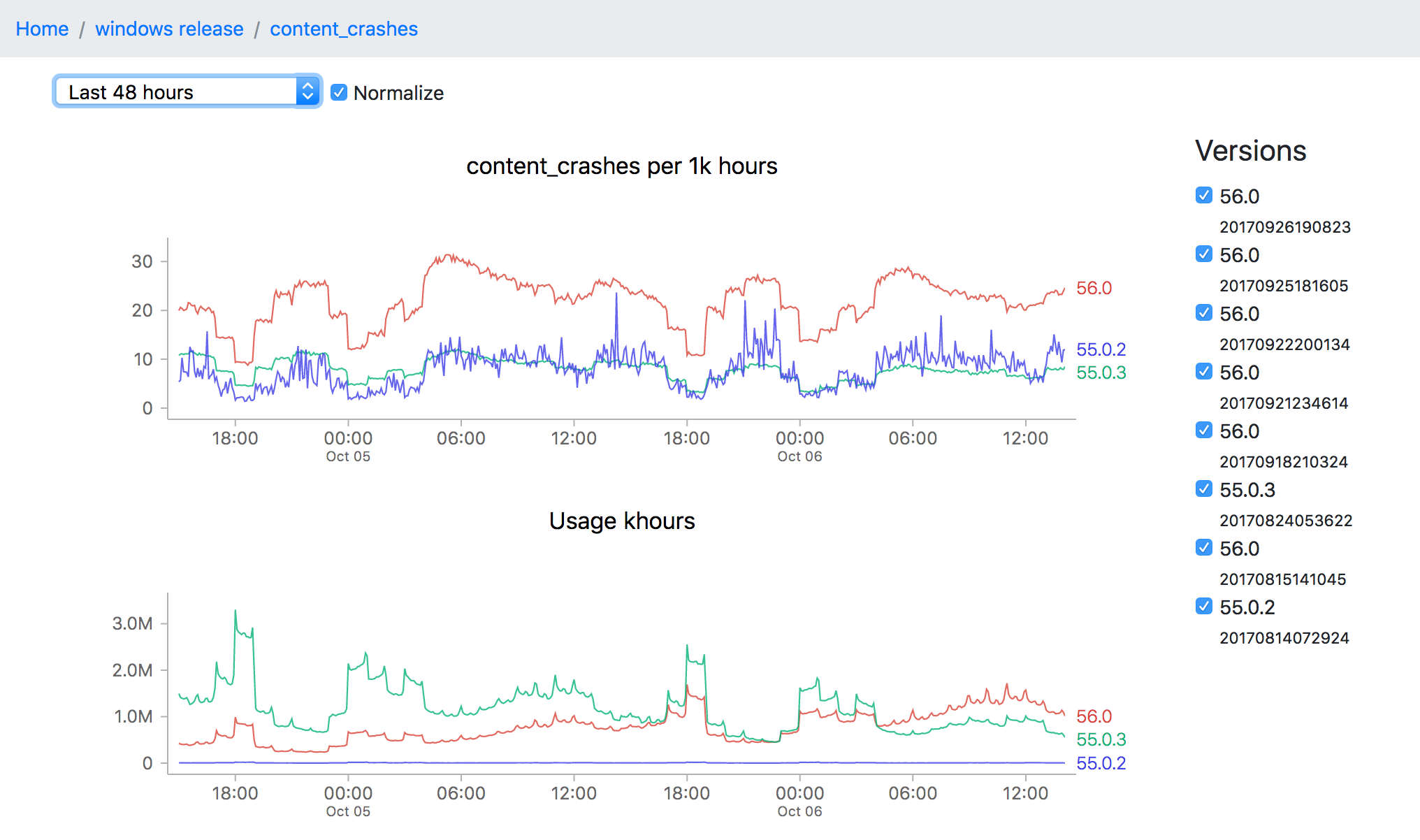
Of course, all this data is not so useful without a tool to visualize it, which is what I’ve been spending the majority of my time on. The idea is to be able to go from a top level description of what’s going on a particular channel (release for example) all the way down to a detailed view of how a measure has been performing over a time interval:
![]()
This particular screenshot shows the volume of content crashes (sampled every 5 minutes) over the last 48 hours on windows release. You’ll note that the later version (56.0) seems to be much crashier than earlier versions (55.0.3) which would seem to be a problem except that the populations are not directly comparable (since the profile of a user still on an older version of Firefox is rather different from that of one who has already upgraded). This is one of the still unsolved problems of this project: finding a reliable, automatable baseline of what an “acceptable result” for any particular measure might be.
Even still, the tool can still be useful for exploring a bunch of data quickly and it has been progressing rapidly over the last few weeks. And like almost everything Mozilla does, both the source and dashboard are open to the public. I’m planning on flagging some easier bugs for newer contributors to work on in the next couple weeks, but in the meantime if you’re interested in this project and want to get involved, feel free to look us up on irc.mozilla.org #missioncontrol (I’m there as ‘wlach’).
Just spent well over an hour tracking down a silly bug in my code. For the mission control project, I wrote this very simple API method that returns a cached data structure to our front end:
def measure(request):
channel_name = request.GET.get('channel')
platform_name = request.GET.get('platform')
measure_name = request.GET.get('measure')
interval = request.GET.get('interval')
if not all([channel_name, platform_name, measure_name]):
return HttpResponseBadRequest("All of channel, platform, measure required")
data = cache.get(get_measure_cache_key(platform_name, channel_name, measure_name))
if not data:
return HttpResponseNotFound("Data not available for this measure combination")
if interval:
try:
min_time = datetime.datetime.now() - datetime.timedelta(seconds=int(interval))
except ValueError:
return HttpResponseBadRequest("Interval must be specified in seconds (as an integer)")
# Return any build data in the interval
empty_buildids = set()
for (build_id, build_data) in data.items():
build_data['data'] = [d for d in build_data['data'] if d[0] > min_time]
if not build_data['data']:
empty_buildids.add(build_id)
# don't bother returning empty indexed data
for empty_buildid in empty_buildids:
del data[empty_buildid]
return JsonResponse(data={'measure_data': data})
As you can see, it takes 3 required parameters (channel, platform, and measure) and one optional one (interval), picks out the required data structure, filters it a bit, and returns it. This is almost what we wanted for the frontend, unfortunately the time zone information isn’t quite what we want, since the strings that are returned don’t tell the frontend that they’re in UTC format — they need a ‘Z’ appended to them for that.
After a bit of digging, I found out that Django’s json serializer will only add the Z if the tzinfo structure is specified. So I figured out a simple pattern for adding that (using the dateutil library, which we are fortunately already using):
from dateutil.tz import tzutc
datetime.datetime.fromtimestamp(mydatestamp.timestamp(), tz=tzutc())
I tested this quickly on the python console and it seemed to work great. But when I added the code to my function, the unit tests mysteriously failed. Can you see why?
for (build_id, build_data) in data.items():
# add utc timezone info to each date, so django will serialize a
# 'Z' to the end of the string (and so javascript's date constructor
# will know it's utc)
build_data['data'] = [
[datetime.datetime.fromtimestamp(d[0].timestamp(), tz=tzutc())] + d[1:] for
d in build_data['data'] if d[0] > min_time
]
Trick question: there’s actually nothing wrong with this code. But if you look at the block in context (see the top of the post), you see that it’s only executed if interval is specified, which it isn’t necessarily. The first case that my unit tests executed didn’t specify interval, so fail they did. It wasn’t immediately obvious to me why this was happening, so I went on a wild-goose chase of trying to figure out how the Django context might have been responsible for the unexpected output, before realizing my basic logic error.
This was fairly easily corrected (my updated code applies the datetime-mapping unconditionally to set of optionally-filtered results) but perfectly illustrates my issue with idiomatic python: while the language itself has constructs like map and reduce that support the functional programming model, the language strongly steers you towards writing things in an imperative style that makes costly and annoying mistakes like this much easier to make. Yes, list and dictionary comprehensions are nice and compact but they start to break down in the more complex cases.
As an experiment, I wrote up what this function might look like in a pure functional style with immutable data structures:
def transform_and_filter_data(build_data):
new_build_data = copy.copy(build_data)
new_build_data['data'] = [
[datetime.datetime.fromtimestamp(d[0].timestamp(), tz=tzutc())] + d[1:] for
d in build_data['data'] if d[0] > min_time
]
return new_build_data
transformed_build_data = {k: v for k, v in {k: transform_and_filter_data(v) for k, v in data}.items() if len(v['data']) > 0}
A work of art it isn’t — and definitely not “pythonic”. Compare this to a similar piece of code written in Javascript (ES6) with lodash (using a hypothetical tzified function):
let transformedBuildData = _.filter(_.mapValues(data, (buildData) => ({
...buildData,
data: buildData.data
.filter(datum => datum[0] > minTimestamp)
.map(datum => [tzcified(datum[0])].concat(datum.slice(1)))
})),
(data, buildId) => data.data.length > 0);
A little bit easier to understand, but more importantly (to me anyway) it comes across as idiomatic and natural in a way that the python version just doesn’t. I’ve been happily programming Python for the last 10 years, but it’s increasingly feeling time to move on to greener pastures.
Spent a few hours this morning on a few housekeeping issues with mozregression. The web site was badly in need of an update (it was full of references to obsolete stuff like B2G and codefirefox.com) and the usual pile of fixes motivated a new release of the actual software. But most importantly, mozregression now has a proper application icon / logo, thanks to Victoria Wang!

One of the nice parts about working at Mozilla is the flexibility it offers to just hack on stuff that’s important, whether or not it’s part of your formal job description. Maintaining mozregression is pretty far outside my current set of responsibilities (or even interests), but I keep it going because it’s a key tool used by developers team here and no one else seems willing to take it over. Fortunately, tools like appveyor and pypi keep the time suckage to a mostly-reasonable level.