Since my last update, we’ve been trucking along with improvements to Perfherder, the project for making Firefox performance sheriffing and analysis easier.
Compare visualization improvements
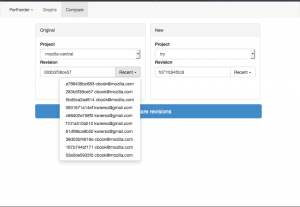
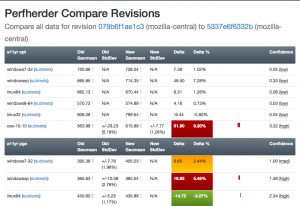
I’ve been spending quite a bit of time trying to fix up the display of information in the compare view, to address feedback from developers and hopefully generally streamline things. Vladan (from the perf team) referred me to Blake Winton, who provided tons of awesome suggestions on how to present things more concisely.
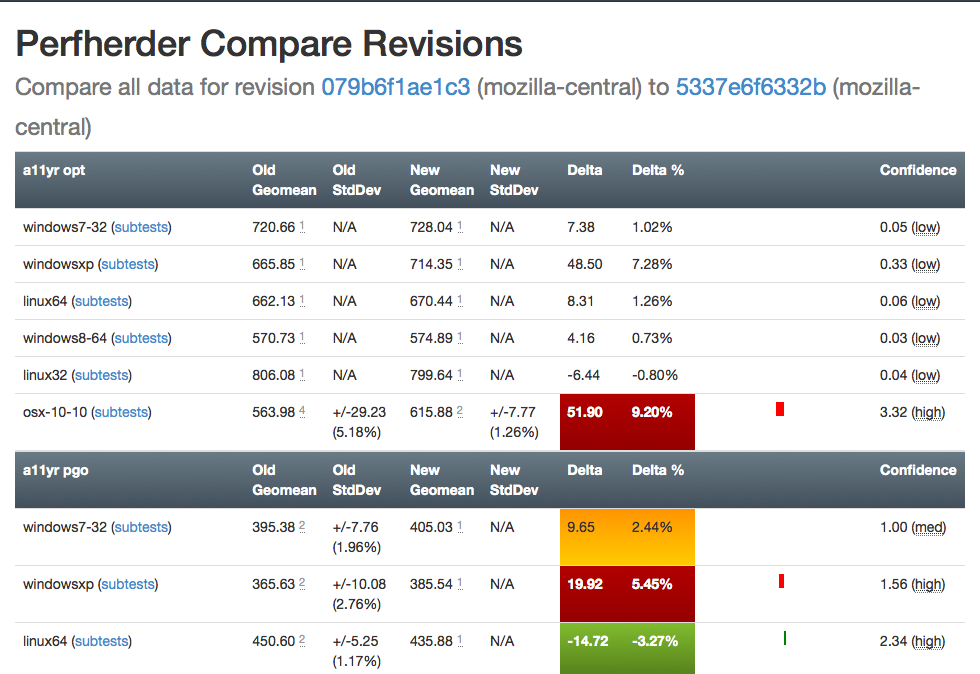
Here’s an old versus new picture:
Summary of significant changes in this view:
- Removed or consolidated several types of numerical information which were overwhelming or confusing (e.g. presenting both numerical and percentage standard deviation in their own columns).
- Added tooltips all over the place to explain what’s being displayed.
- Highlight more strongly when it appears there aren’t enough runs to make a definitive determination on whether there was a regression or improvement.
- Improve display of visual indicator of magnitude of regression/improvement (providing a pseudo-scale showing where the change ranges from 0% : 20%+).
- Provide more detail on the two changesets being compared in the header and make it easier to retrigger them (thanks to Mike Ling).
- Much better and more intuitive error handling when something goes wrong (also thanks to Mike Ling).
The point of these changes isn’t necessarily to make everything “immediately obvious” to people. We’re not building general purpose software here: Perfherder will always be a rather specialized tool which presumes significant domain knowledge on the part of the people using it. However, even for our audience, it turns out that there’s a lot of room to improve how our presentation: reducing the amount of extraneous noise helps people zero in on the things they really need to care about.
Special thanks to everyone who took time out of their schedules to provide so much good feedback, in particular Avi Halmachi, Glandium, and Joel Maher.
Of course more suggestions are always welcome. Please give it a try and file bugs against the perfherder component if you find anything you’d like to see changed or improved.
Getting the word out
Hammersmith:mozilla-central wlach$ hg push -f try
pushing to ssh://hg.mozilla.org/try
no revisions specified to push; using . to avoid pushing multiple heads
searching for changes
remote: waiting for lock on repository /repo/hg/mozilla/try held by 'hgssh1.dmz.scl3.mozilla.com:8270'
remote: got lock after 4 seconds
remote: adding changesets
remote: adding manifests
remote: adding file changes
remote: added 1 changesets with 1 changes to 1 files
remote: Trying to insert into pushlog.
remote: Inserted into the pushlog db successfully.
remote:
remote: View your change here:
remote: https://hg.mozilla.org/try/rev/e0aa56fb4ace
remote:
remote: Follow the progress of your build on Treeherder:
remote: https://treeherder.mozilla.org/#/jobs?repo=try&revision=e0aa56fb4ace
remote:
remote: It looks like this try push has talos jobs. Compare performance against a baseline revision:
remote: https://treeherder.mozilla.org/perf.html#/comparechooser?newProject=try&newRevision=e0aa56fb4ace
Try pushes incorporating Talos jobs now automatically link to perfherder’s compare view, both in the output from mercurial and in the emails the system sends. One of the challenges we’ve been facing up to this point is just letting developers know that Perfherder exists and it can help them either avoid or resolve performance regressions. I believe this will help.
Data quality and ingestion improvements
Over the past couple weeks, we’ve been comparing our regression detection code when run against Graphserver data to Perfherder data. In doing so, we discovered that we’ve sometimes been using the wrong algorithm (geometric mean) to summarize some of our tests, leading to unexpected and less meaningful results. For example, the v8_7 benchmark uses a custom weighting algorithm for its score, to account for the fact that the things it tests have a particular range of expected values.
To hopefully prevent this from happening again in the future, we’ve decided to move the test summarization code out of Perfherder back into Talos (bug 1184966). This has the additional benefit of creating a stronger connection between the content of the Talos logs and what Perfherder displays in its comparison and graph views, which has thrown people off in the past.
Continuing data challenges
Having better tools for visualizing this stuff is great, but it also highlights some continuing problems we’ve had with data quality. It turns out that our automation setup often produces qualitatively different performance results for the exact same set of data, depending on when and how the tests are run.
A certain amount of random noise is always expected when running performance tests. As much as we might try to make them uniform, our testing machines and environments are just not 100% identical. That we expect and can deal with: our standard approach is just to retrigger runs, to make sure we get a representative sample of data from our population of machines.
The problem comes when there’s a pattern to the noise: we’ve already noticed that tests run on the weekends produce different results (see Joel’s post from a year ago, “A case of the weekends”) but it seems as if there’s other circumstances where one set of results will be different from another, depending on the time that each set of tests was run. Some tests and platforms (e.g. the a11yr suite, MacOS X 10.10) seem particularly susceptible to this issue.
We need to find better ways of dealing with this problem, as it can result in a lot of wasted time and energy, for both sheriffs and developers. See for example bug 1190877, which concerned a completely spurious regression on the tresize benchmark that was initially blamed on some changes to the media code: in this case, Joel speculates that the linux64 test machines we use might have changed from under us in some way, but we really don’t know yet.
I see two approaches possible here:
- Figure out what’s causing the same machines to produce qualitatively different result distributions and address that. This is of course the ideal solution, but it requires coordination with other parts of the organization who are likely quite busy and might be hard.
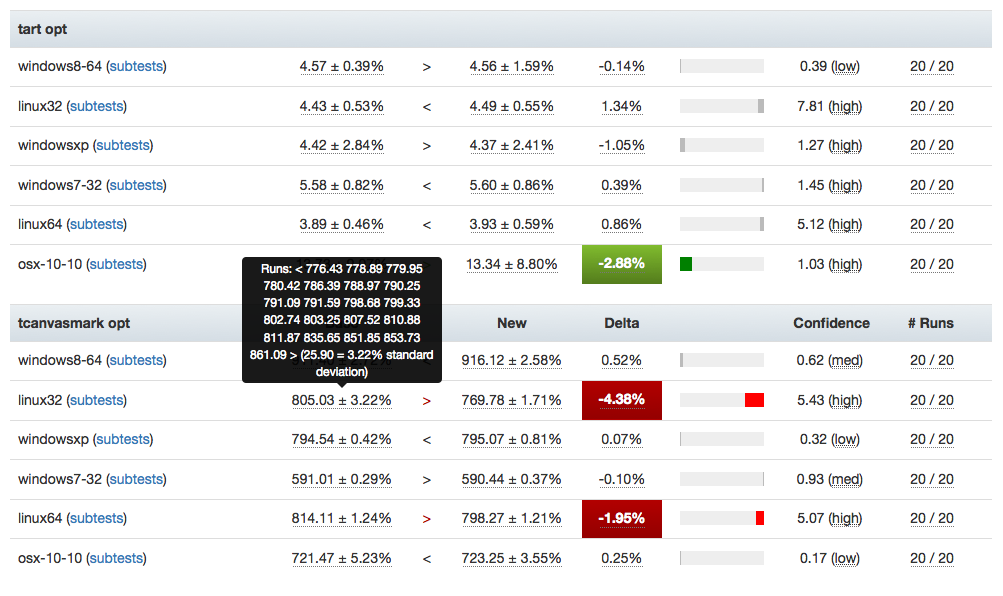
- Figure out better ways of detecting and managing these sorts of case. I have noticed that the standard deviation inside the results when we have spurious regressions/improvements tends to be higher (see for example this compare view for the aforementioned “regression”). Knowing what we do, maybe there’s some statistical methods we can use to detect bad data?
For now, I’m leaning towards (2). I don’t think we’ll ever completely solve this problem and I think coming up with better approaches to understanding and managing it will pay the largest dividends. Open to other opinions of course!
Haven’t been doing enough blogging about Perfherder (our project to make Talos and other per-checkin performance data more useful) recently. Let’s fix that. We’ve been making some good progress, helped in part by a group of new contributors that joined us through an experimental "summer of contribution" program.
Comparison mode
Inspired by Compare Talos, we’ve designed something similar which hooks into the perfherder backend. This has already gotten some interest: see this post on dev.tree-management and this one on dev.platform. We’re working towards building something that will be really useful both for (1) illustrating that the performance regressions we detect are real and (2) helping developers figure out the impact of their changes before they land them.
 |
 |
Most of the initial work was done by Joel Maher with lots of review for aesthetics and correctness by me. Avi Halmachi from the Performance Team also helped out with the t-test model for detecting the confidence that we have that a difference in performance was real. Lately myself and Mike Ling (one of our summer of contribution members) have been working on further improving the interface for usability — I’m hopeful that we’ll soon have something implemented that’s broadly usable and comprehensible to the Mozilla Firefox and Platform developer community.
Graphs improvements
Although it’s received slightly less attention lately than the comparison view above, we’ve been making steady progress on the graphs view of performance series. Aside from demonstrations and presentations, the primary use case for this is being able to detect visually sustained changes in the result distribution for talos tests, which is often necessary to be able to confirm regressions. Notable recent changes include a much easier way of selecting tests to add to the graph from Mike Ling and more readable/parseable urls from Akhilesh Pillai (another summer of contribution participant).
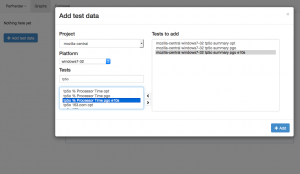
Performance alerts
I’ve also been steadily working on making Perfherder generate alerts when there is a significant discontinuity in the performance numbers, similar to what GraphServer does now. Currently we have an option to generate a static CSV file of these alerts, but the eventual plan is to insert these things into a peristent database. After that’s done, we can actually work on creating a UI inside Perfherder to replace alertmanager (which currently uses GraphServer data) and start using this thing to sheriff performance regressions — putting the herder into perfherder.
As part of this, I’ve converted the graphserver alert generation code into a standalone python library, which has already proven useful as a component in the Raptor project for FirefoxOS. Yay modularity and reusability.
Python API
I’ve also been working on creating and improving a python API to access Treeherder data, which includes Perfherder. This lets you do interesting things, like dynamically run various types of statistical analysis on the data stored in the production instance of Perfherder (no need to ask me for a database dump or other credentials). I’ve been using this to perform validation of the data we’re storing and debug various tricky problems. For example, I found out last week that we were storing up to duplicate 200 entries in each performance series due to double data ingestion — oops.
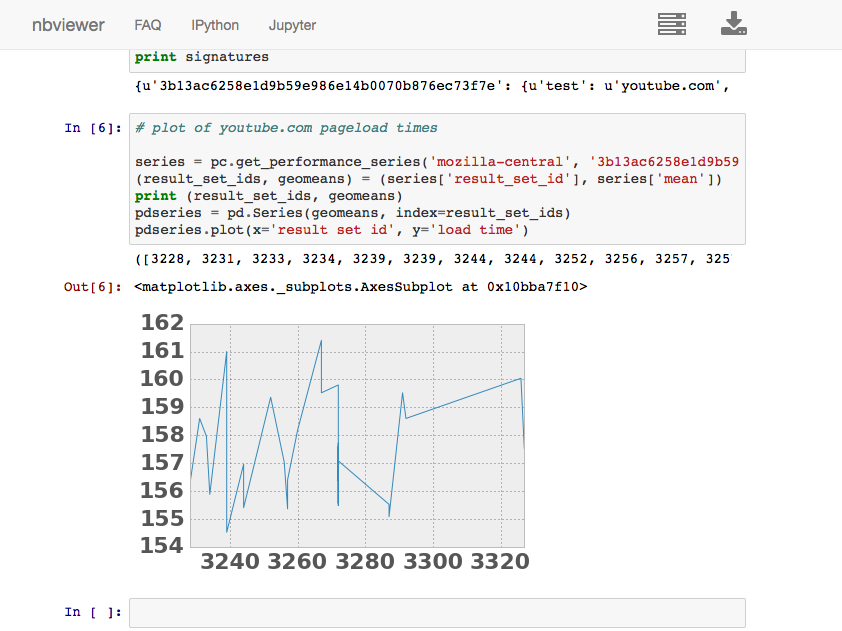
You can also use this API to dynamically create interesting graphs and visualizations using ipython notebook, here’s a simple example of me plotting the last 7 days of youtube.com pageload data inline in a notebook:
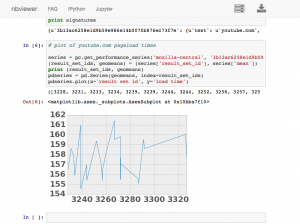
[original]
Was feeling a bit restless today, so I decided to build something on a theme I’d been thinking of since, oh gosh, I guess high school — an ecosystem simulation.
My original concept for it had three different types of entities — grass, rabbits, and foxes wandering around in a fixed environment. Each would eat the previous and try to reproduce. Both the rabbits and foxes need to continually eat to survive, otherwise they will die. The grass will just grow unprompted. I think I may have picked up the idea from elsewhere, but am not sure (it’s been nearly 17 years after all).
I suppose the urge to do this comes from my fascination with the concepts of birth, death, and rebirth. Conway’s game of life is probably the most famous computer representation of this sort of theme, but I always found the behavior slightly too contrived and simple to be deeply satisfying to me (at least from the point of view of representing this concept: the game is certainly interesting for other reasons). Conway’s simulation is completely deterministic and only has one type of entity, the cell. There’s an element of randomness and hierarchy in the real world, and I wanted to represent these somehow.
It was remarkably easy to get things going using my preferred toolkit for these things (Javascript and Canvas) — about 3 hours to get something on the screen, then a bunch of tweaking until I found the behavior I wanted. Either I’m getting smarter or the tools to build these things are getting better. Probably the latter.
In the end, I only wound up having rabbits and grass in my simulation in this iteration and went for a very abstract representation of what was going on (colored squares for everything!). It turns out that no more than that was really necessary to create something that held my interest. Here’s a screenshot (doesn’t really do it justice):

If you’d like to check it out for yourself, I put a copy on my website here. It probably requires a fairly fancy computer to run at a decent speed (I built it using a 2014 MacBook Pro and made very little effort to optimize it). If that doesn’t work out for you, I put up a video capture of the simulation on youtube.
The math and programming behind the simulation is completely arbitrary and anything but rigorous. There are probably a bunch of bugs and unintended behaviors. This has all probably been done a million times before by people I’ve never met and never will. I’m ok with that.
Update: Source now on github, for those who want to play with it and submit pull requests.
So I went to PyCon 2015. While I didn’t leave quite as inspired as I did in 2014 (when I discovered iPython), it was a great experience and I learned a ton. Once again, I was incredibly impressed with the organization of the conference and the diversity and quality of the speakers.
Since Mozilla was nice enough to sponsor my attendance, I figured I should do another round up of notable talks that I went to.
Technical stuff that was directly relevant to what I work on:
- To ORM or not to ORM (Christine Spang): Useful talk on when using a database ORM (object relational manager) can be helpful and even faster than using a database directly. I feel like there’s a lot of misinformation and FUD on this topic, so this was refreshing to see. video slides
- Debugging hard problems (Alex Gaynor): Exactly what it says — how to figure out what’s going on when things aren’t behaving as they should. Great advice and wisdom in this one (hint: take nothing for granted, dive into the source of everything you’re using!). video slides
- Python Performance Profiling: The Guts And The Glory (Jesse Jiryu Davis): Quite an entertaining talk on how to properly profile python code. I really liked his systematic and realistic approach — which also discussed the thought process behind how to do this (hint: again it comes down to understanding what’s really going on). Unfortunately the video is truncated, but even the first few minutes are useful. video
Non-technical stuff:
- The Ethical Consequences Of Our Collective Activities (Glyph): A talk on the ethical implications of how our software is used. I feel like this is an under-discussed topic — how can we know that the results of our activity (programming) serves others and does not harm? video
- How our engineering environments are killing diversity (and how we can fix it) (Kate Heddleston): This was a great talk on how to make the environments in which we develop more welcoming to under-represented groups (women, minorities, etc.). This is something I’ve been thinking a bunch about lately, especially in the context of expanding the community of people working on our projects in Automation & Tools. The talk had some particularly useful advice (to me, anyway) on giving feedback. video slides
I probably missed out on a bunch of interesting things. If you also went to PyCon, please feel free to add links to your favorite talks in the comments!
Just wanted to give another quick Perfherder update. Since the last time, I’ve added summary series (which is what GraphServer shows you), so we now have (in theory) the best of both worlds when it comes to Talos data: aggregate summaries of the various suites we run (tp5, tart, etc), with the ability to dig into individual results as needed. This kind of analysis wasn’t possible with Graphserver and I’m hopeful this will be helpful in tracking down the root causes of Talos regressions more effectively.
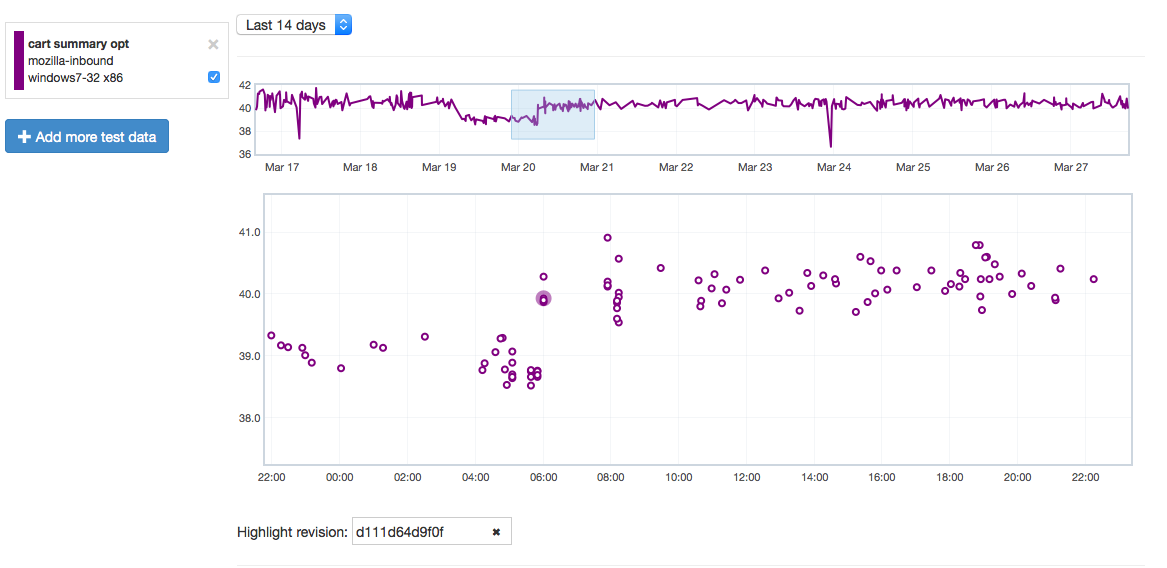
Let’s give an example of where this might be useful by showing how it can highlight problems. Recently we tracked a regression in the Customization Animation Tests (CART) suite from the commit in bug 1128354. Using Mishra Vikas‘s new “highlight revision mode” in Perfherder (combined with the revision hash when the regression was pushed to inbound), we can quickly zero in on the location of it:
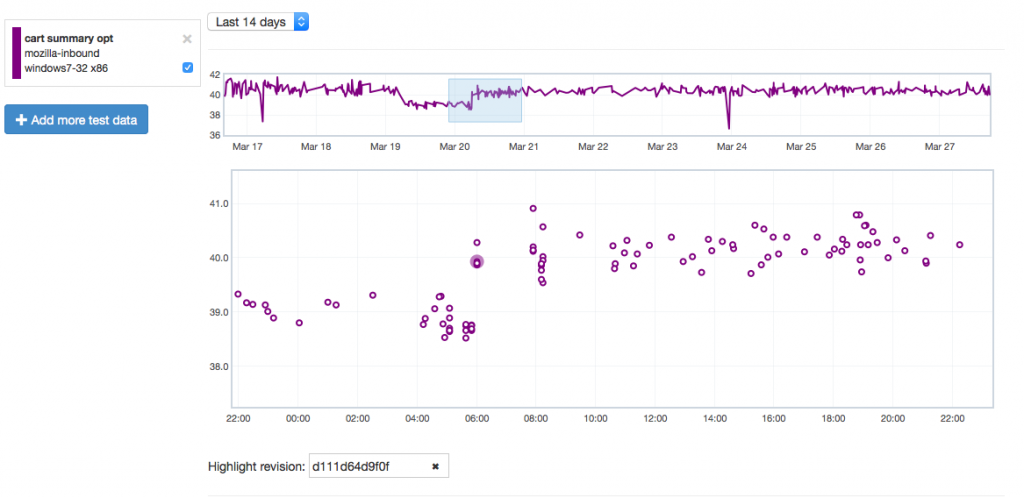
It does indeed look like things ticked up after this commit for the CART suite, but why? By clicking on the datapoint, you can open up a subtest summary view beneath the graph:
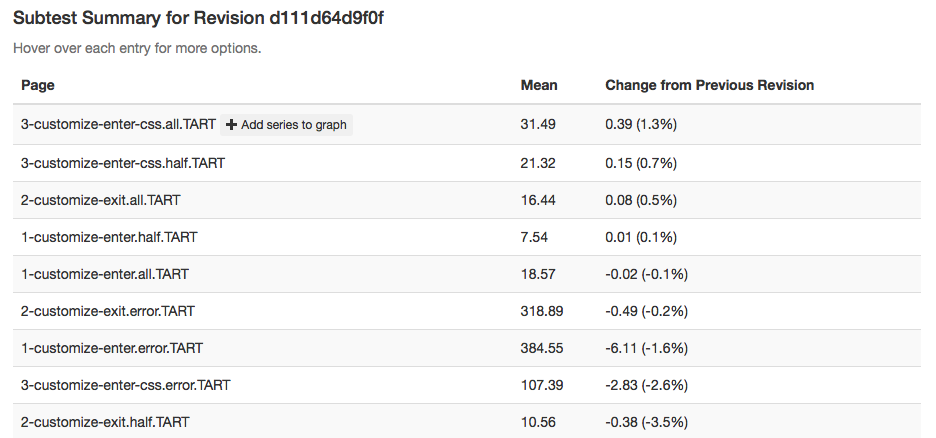
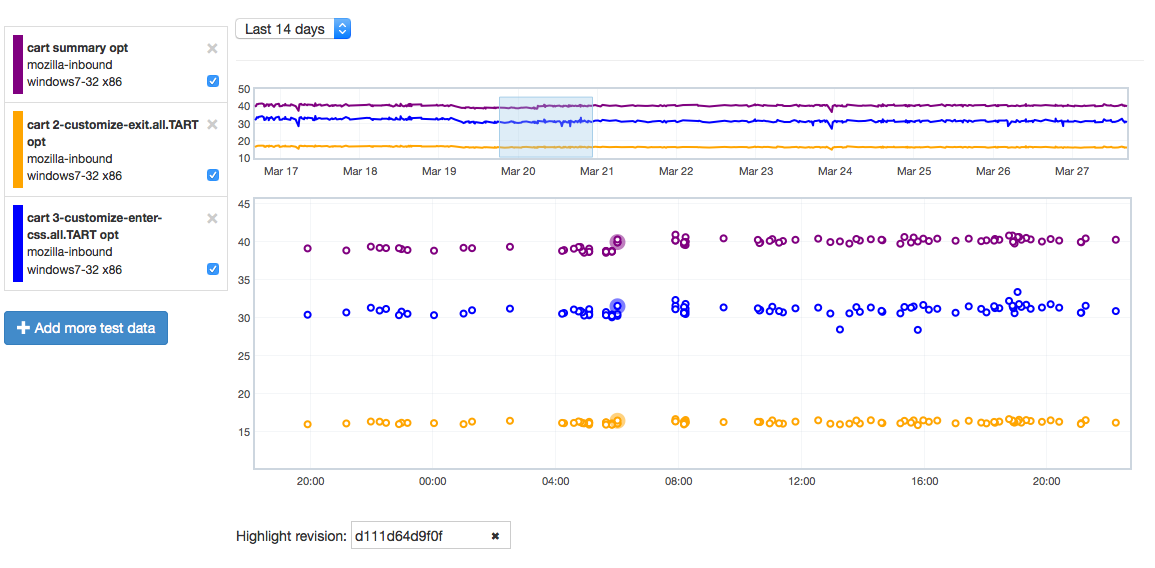
We see here that it looks like the 3-customize-enter-css.all.TART entry ticked up a bunch. The related test 3-customize-enter-css.half.TART ticked up a bit too. The changes elsewhere look minimal. But is that a trend that holds across the data over time? We can add some of the relevant subtests to the overall graph view to get a closer look:
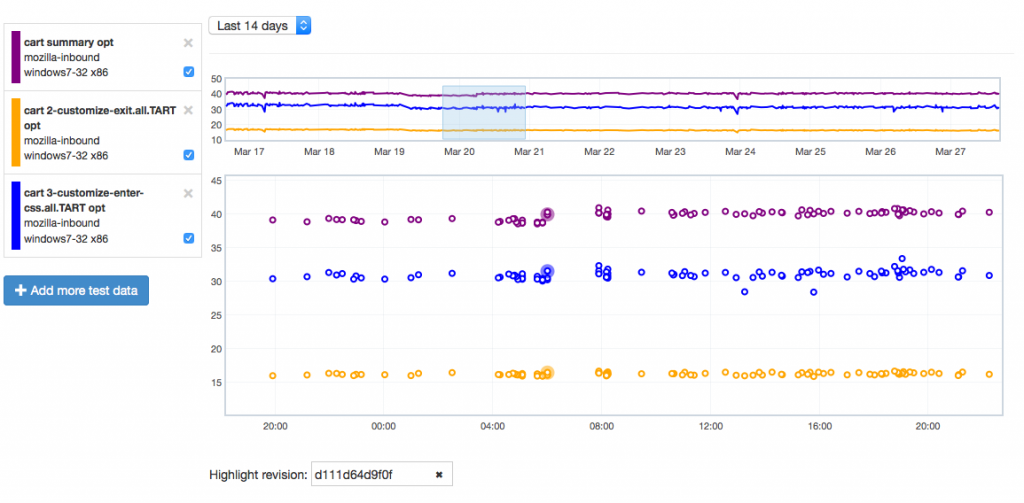
As is hopefully obvious, this confirms that the affected subtest continues to hold its higher value while another test just bounces around more or less in the range it was before.
Hope people find this useful! If you want to play with this yourself, you can access the perfherder UI at http://treeherder.mozilla.org/perf.html.
For the past few months I’ve been working on a sub-project of Treeherder called Perfherder, which aims to provide a workflow that will let us more easily detect and manage performance regressions in our products (initially just those detected in Talos, but there’s room to expand on that later). This is a long term project and we’re still sorting out the details of exactly how it will work, but I thought I’d quickly announce a milestone.
As a first step, I’ve been hacking on a graphical user interface to visualize the performance data we’re now storing inside Treeherder. It’s pretty bare bones so far, but already it has two features which graphserver doesn’t: the ability to view sub-test results (i.e. the page load time for a specific page in the tp5 suite, as opposed to the geometric mean of all of them) and the ability to see results for e10s builds.
Here’s an example, comparing the tp5o 163.com page load times on windows 7 with e10s enabled (and not):
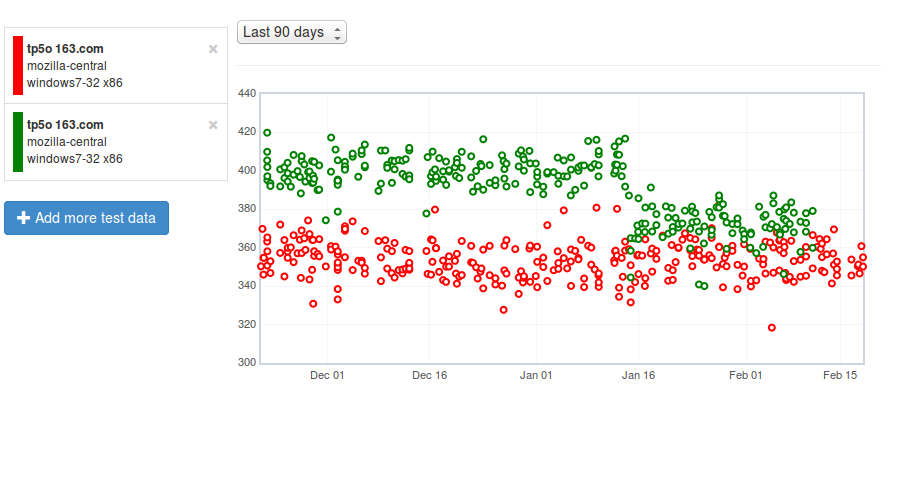
[link]
Green is e10s, red is non-e10s (the legend picture doesn’t reflect this because we have yet to deploy a fix to bug 1130554, but I promise I’m not lying). As you can see, the gap has been closing (in particular, something landed in mid-January that improved the e10s numbers quite a bit), but page load times are still measurably slower with this feature enabled.
Lots of movement in mozregression (a tool for automatically determining when a regression was introduced in Firefox by bisecting builds on ftp.mozilla.org) in the last few months. Here’s some highlights:
- Support for win64 nightly and inbound builds (Kapil Singh, Vaibhav Agarwal)
- Support for using an http cache to reduce time spent downloading builds (Sam Garrett)
- Way better logging and printing of remaining time to finish bisection (Julien Pagès)
- Much improved performance when bisecting inbound (Julien)
- Support for automatic determination on whether a build is good/bad via a custom script (Julien)
- Tons of bug fixes and other robustness improvements (me, Sam, Julien, others)
Also thanks to Julien, we have a spiffy new website which documents many of these features. If it’s been a while, be sure to update your copy of mozregression to the latest version and check out the site for documentation on how to use the new features described above!
Thanks to everyone involved (especially Julien) for all the hard work. Hopefully the payoff will be a tool that’s just that much more useful to Firefox contributors everywhere.
Just a quick note that my campaign to raise funds for MSF was successful. From friends and family, coworkers, and my extended network I managed to raise the sum of $3106. This was a bit above my maximum of $2500 that I said I would match, but what the hell:

So in total that means $6212 for Doctors without Borders. Not half bad for a week long campaign from someone as insignificant as myself!
Most of the people who donated wanted to remain anonymous, which is cool. But among those who were cool about being public, big thanks to: Julia Evans, Chris Atlee, Mike Conley, Ted Tibbetts, Paul and Eva Lachance, Alex Demarsh and Lauren Reid (if I’m missing someone who wants to be named, please let me know).
Incidentally, I’ve learned a bit more about Ebola over the past week, and I’m fairly sure that we’ll be ok here in Canada and the States given the fact that the virus isn’t actually that contagious (and that we have reasonable facilities for treating it in a safe manner, major screwups in Dallas notwithstanding). Liberia and other parts of Africa are still very much worth worrying about though, so I still 100% that starting this campaign was the right thing for me to do as an individual. Actually wiping out the disease will likely require government-level resources and intervention. Still waiting for a more serious resource commitment from Canada (cautiously optimistic about what’s happening with the States).
I’ve been appalled at the (lack of) response to the Ebola epidemic in Africa. We’re talking about a deadly disease which could infect more than a million people by January 2015 and explode out of control but the response from our governments has been pitiful, ranging from “inadequate” in the case of the United States to “pretty much nothing” from Canada.
Closer to home, my friends and acquaintances seem more interested in trading cute quips (“Want to get space on public transit? Pretend to have a conversation on your cellphone about how you just came home from Liberia!” LOL) and image captures from CNN and Fox News saying dumb things (“Is Ebola the ISIS of epidemics?”) than anything else.
I don’t really know how to emphasize how serious this situation is. Yes, there are a million causes and issues competing for people’s attention these days. But Ebola is an epidemic. Many, many people could die. Even more could suffer. In the extreme case, this could be the end of civilization as we know it. Some kind of action is called for.
I don’t have any medical expertise, otherwise I’d probably be offering to volunteer abroad. The most I have to offer is money and a very modest circle of influence. So be it, that will have to do. I’m not going to sit back and do nothing while this happens.
Doctors without Borders seem to be the non-profit organiztion who have been able to do the most to be able to respond to this situation (and they’ve generally gotten good reviews in the past as a no-nonsense humanitarian group responding to crises all over the world). For the next week, I will match dollar for dollar any contribution (of any amount) that anyone donates to this organization, up to a maximum of $2500 (total across all contributions). Just email me at wrlach@gmail.com with your donation and whether you’d like to remain anonymous.
At the end of this coming week (Sunday, October 19th), I’ll donate the matching funds to MSF and do up another blog post with the results and the names of the people who donated and consented to have their names published. The world needs to know that I’m not the only one that cares about this.
Over last few months, I discovered the joy that is CSS Flexbox, which solves the “how do I lay out this set of div’s in horizontally or vertically”. I’ve used it in three projects so far:
- Centering the timer interface in my meditation app, so that it scales nicely from a 320×480 FirefoxOS device all the way up to a high definition monitor
- Laying out the chart / sidebar elements in the Eideticker dashboard so that maximum horizontal space is used
- Fixing various problems in the Treeherder UI on smaller screens (see bug 1043474 and its dependent bugs)
When I talk to people about their troubles with CSS, layout comes up really high on the list. Historically, basic layout problems like a panel of vertical buttons have been ridiculously difficult, involving hacks involving floating divs and absolute positioning or JavaScript layout libraries. This is why people write articles entitled “Give up and use tables”.
Flexbox has pretty much put an end to these problems for me. There’s no longer any need to “give up and use tables” because using flexbox is pretty much just *like* using tables for layout, just with more uniform and predictable behaviour. They’re so great. I think we’re pretty close to Flexbox being supported across all the major browsers, so it’s fair to start using them for custom web applications where compatibility with (e.g.) IE8 is not an issue.
To try and spread the word, I wrote up a howto article on using flexbox for web applications on MDN, covering some of the common use cases I mention above. If you’ve been curious about flexbox but unsure how to use it, please have a look.